Le modèle frontend-backend ne suffit plus à décrire les systèmes modernes
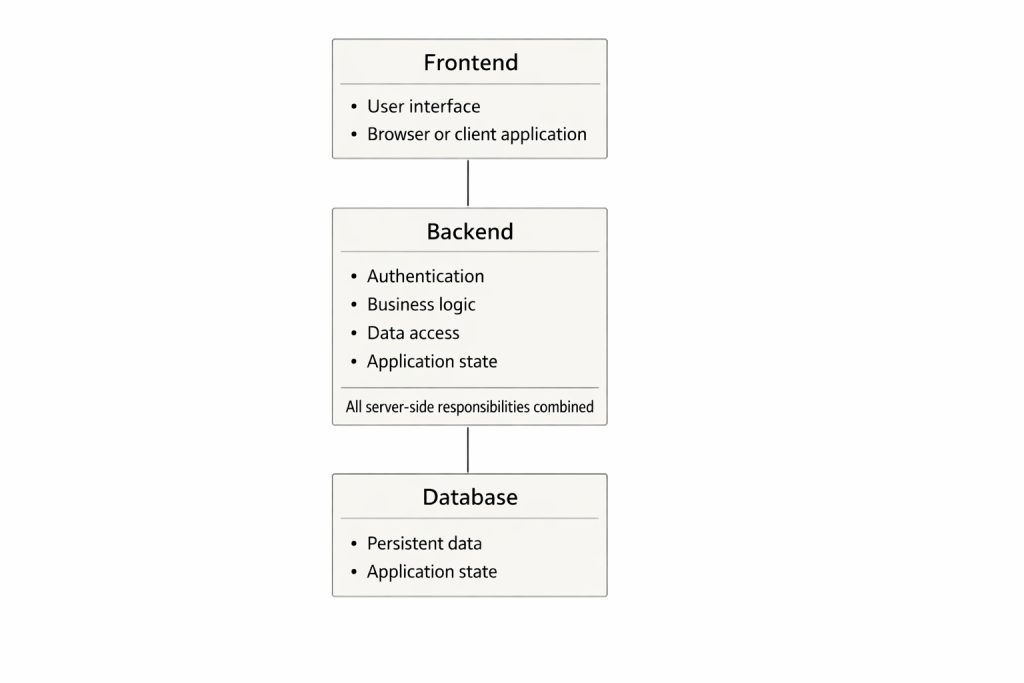
La séparation entre frontend et backend constitue depuis des décennies l’un des fondements de l’ingénierie logicielle. Elle est simple, facile à enseigner et pédagogiquement efficace, ce qui explique pourquoi elle demeure largement présente dans les universités et les programmes de formation. L’interface utilisateur se trouve à l’avant, le serveur à l’arrière, et la base de données encore plus loin. L’utilisateur envoie une requête, le backend la traite et renvoie une réponse. Le modèle est logique et intuitif – mais il s’éloigne de plus en plus de la réalité dans laquelle fonctionnent les systèmes contemporains.
Cela ne signifie pas que la pensée frontend-backend ait été erronée. Bien au contraire : elle a constitué une abstraction historiquement nécessaire. Le problème apparaît lorsqu’elle devient un point d’arrivée plutôt qu’un point de départ conceptuel. À mesure que les systèmes grandissent, que le nombre d’utilisateurs se multiplie et que les exigences en matière de performance, de disponibilité et de sécurité se renforcent, un modèle à deux blocs ne suffit plus à représenter la structure réelle d’un système – et encore moins la répartition effective des responsabilités.
Origines historiques et limites du modèle
Le modèle frontend-backend originel est né à une époque où les applications étaient souvent monolithiques. Un seul processus serveur regroupait l’authentification, la logique métier, la gestion de l’état et l’accès aux bases de données. L’interface utilisateur constituait une couche mince reposant sur cet ensemble. Toutes les responsabilités côté serveur étaient concentrées dans une seule entité, et cette approche a longtemps été parfaitement fonctionnelle.
Dans ce contexte, l’amélioration des performances passait principalement par une montée en puissance verticale : davantage de mémoire, des processeurs plus rapides, des supports de stockage plus performants. La mise à l’échelle signifiait des machines plus grandes. La sécurité relevait en grande partie de la logique applicative, et la gestion du trafic s’effectuait souvent profondément à l’intérieur de l’application. Ce modèle reste pertinent pour de petits systèmes et des cas d’usage simples, et il ne doit pas être dévalorisé.
C’est précisément pour cette raison qu’il devient dangereux comme base pédagogique si l’on s’y attarde trop longtemps. Il donne l’image d’un système linéaire, d’un pipeline unique dans lequel tout se déroule de manière séquentielle, et où chaque requête parcourt l’intégralité de la chaîne, qu’elle en ait besoin ou non.
L’élargissement de la pensée north-south
Le modèle frontend-backend classique repose presque exclusivement sur le trafic north-south. La requête de l’utilisateur descend à travers le système, est traitée, puis une réponse remonte. Cette vision était naturelle à une époque où les systèmes étaient simples et où les communications internes restaient limitées.
Avec la distribution croissante des systèmes et l’augmentation de leur complexité, il est devenu nécessaire de distinguer le trafic externe du trafic interne. Les services ont commencé à communiquer entre eux, les données ont été synchronisées en arrière-plan, et la coordination interne est devenue une part significative de la charge globale. À ce stade, le trafic east-west a pris une importance comparable à celle du trafic orienté utilisateur.
Il ne s’agissait pas uniquement d’un changement technique, mais d’un changement de paradigme. Le système n’était plus un simple pipeline, mais un écosystème. Tous les flux n’avaient pas la même valeur, et tous ne devaient pas emprunter le même chemin.
Une transformation architecturale
Lorsque les flux north-south et east-west sont distingués, la structure du système se transforme en profondeur. L’architecture ne s’organise plus autour d’un composant central unique, mais se stratifie naturellement en fonction des responsabilités. Le trafic externe peut être reçu, interprété et, si nécessaire, limité dès la périphérie du système, avant de solliciter la logique applicative ou les données persistantes. Parallèlement, le trafic interne peut être optimisé selon d’autres critères : fiabilité, cohérence et observabilité deviennent prioritaires.
Cette transformation n’est pas uniquement technique, elle est également conceptuelle. Lorsqu’un système est perçu comme l’interaction de plusieurs flux de communication, il n’a plus besoin de se présenter comme un « backend » unique et homogène. Il en résulte un modèle multicouche dans lequel chaque niveau assume une mission précise et une responsabilité clairement délimitée. Aucun niveau ne cherche à résoudre l’ensemble du problème ; chacun se concentre sur sa part. Cela réduit les couplages internes et rend l’ensemble plus intelligible – non pas comme une boîte isolée, mais comme une structure organisée.
Du point de vue de l’utilisateur, ce changement reste généralement invisible. L’utilisateur n’interagit plus avec « le backend », mais avec plusieurs niveaux du système, sans que cela n’apparaisse dans l’interface. La requête progresse étape par étape, et chaque niveau décide s’il est pertinent qu’elle continue son chemin. Le système ressemble alors davantage à un processus délibératif qu’à un flux linéaire.
C’est précisément cette capacité de discernement qui constitue le cœur du modèle multicouche. Chaque niveau accomplit moins de tâches qu’un backend traditionnel, mais les réalise de manière plus consciente et plus maîtrisée. Les responsabilités ne disparaissent pas ; elles se déplacent vers les endroits où elles peuvent être exercées plus efficacement. L’architecture ne devient pas complexe parce que l’on ajoute arbitrairement des couches, mais parce que la réalité elle-même est complexe. La stratification permet de rendre cette complexité visible – et donc maîtrisable.
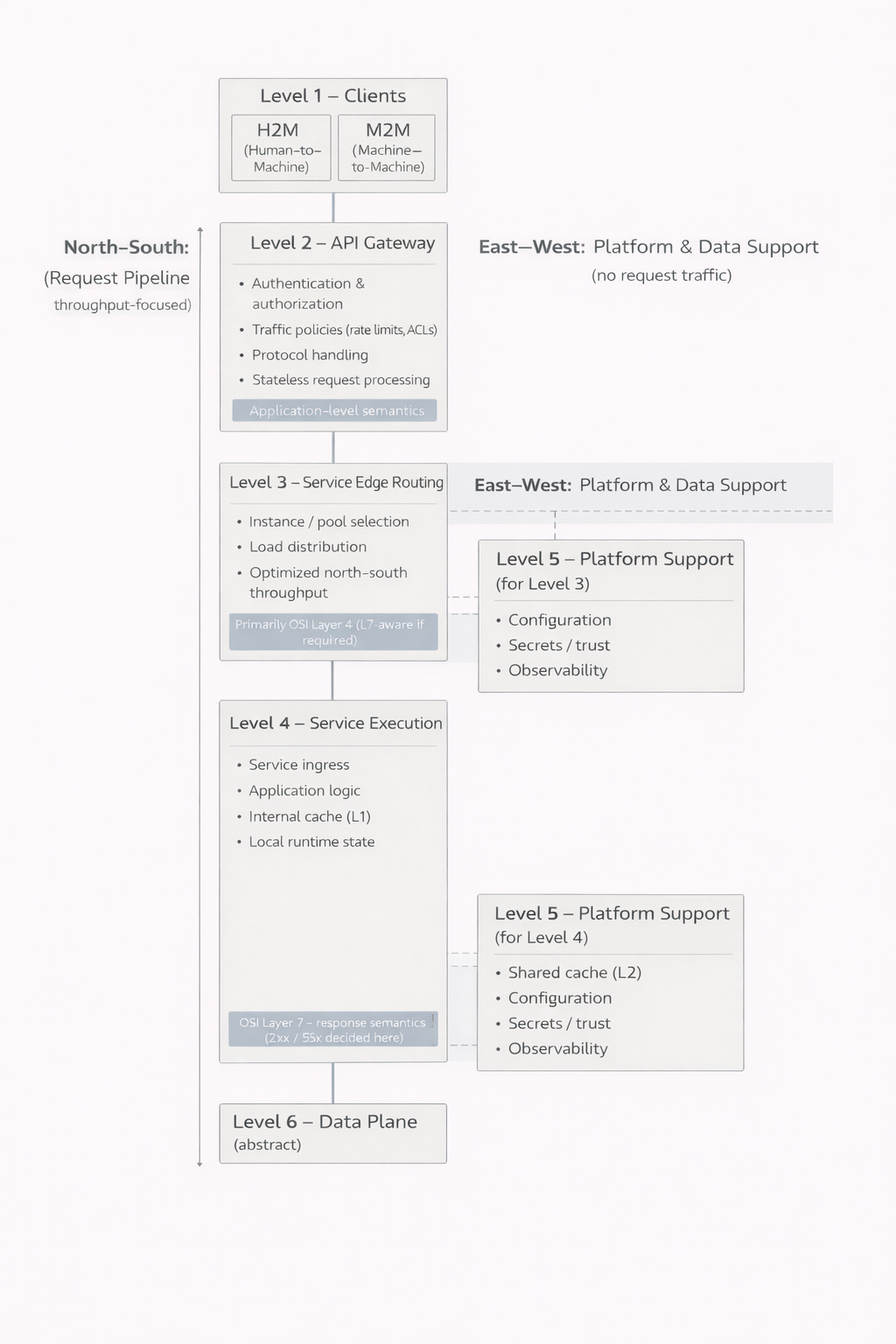
Les niveaux 1 à 6 comme ensemble cohérent
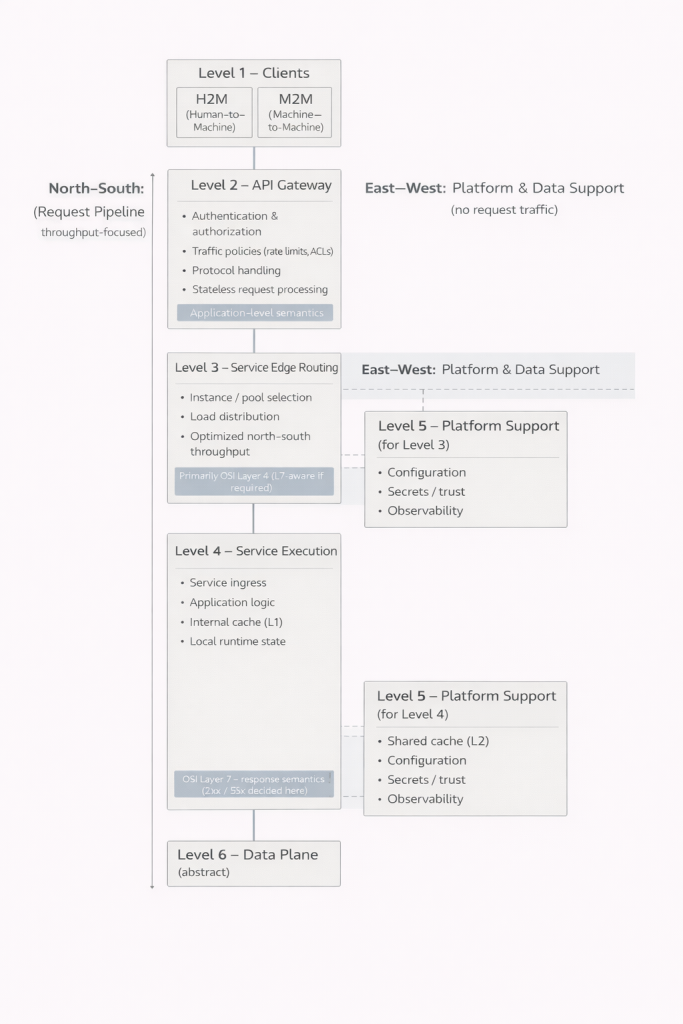
Le premier niveau correspond aux clients. Les interfaces utilisées par les humains et les intégrations entre machines peuvent sembler similaires en apparence, mais leurs exigences et leurs comportements peuvent différer profondément. Cette distinction est essentielle, car le système doit être capable de servir les deux de manière contrôlée.
Le deuxième niveau constitue l’interface entre le système et le monde extérieur. C’est là que s’opèrent l’authentification, l’autorisation, la limitation du trafic et, souvent, la gestion des protocoles. Un point fondamental est que toutes les requêtes ne dépassent pas ce stade. Une authentification invalide, des droits insuffisants ou des limites dépassées peuvent être rejetés immédiatement. Cela réduit la charge sur les niveaux plus profonds du système et améliore à la fois les performances et la sécurité.
Le troisième niveau est responsable de l’orientation du trafic vers les services appropriés. Dans les petits systèmes, il peut être intégré au niveau suivant et ne pas être identifié comme une entité distincte. Lorsque le nombre d’utilisateurs et d’instances augmente, il devient toutefois indispensable. Il permet la répartition de charge, l’isolation des défaillances et une mise à l’échelle contrôlée.
Le quatrième niveau est celui où s’effectue le travail réel de l’application. La logique métier, la construction des réponses et la gestion de l’état local y prennent place. Il est crucial de comprendre que ce niveau n’est pas nécessairement monolithique. Il peut être composé de plusieurs éléments parallèles servant un même objectif. Cela permet de mettre à jour ou de retirer une partie du service sans interrompre l’ensemble. L’utilisateur peut ne rien percevoir, même lorsque des changements importants se produisent au cœur du système.
Le cinquième niveau introduit la dimension opérationnelle. Les configurations, les relations de confiance, la gestion des secrets et l’observabilité ne relèvent pas de la logique métier, mais sont indispensables à un fonctionnement sûr et fiable. Dans les petits systèmes, ces responsabilités sont souvent dissimulées et intégrées ailleurs. À mesure que le système grandit, elles émergent inévitablement comme des préoccupations distinctes.
Le sixième niveau est celui des données. Il est volontairement présenté de manière abstraite, car il mérite une analyse spécifique. Fichiers, relations, événements et flux constituent la base sur laquelle repose l’ensemble du système. Plus une requête s’enfonce dans ce niveau, plus elle tend à devenir coûteuse et lente. C’est précisément pour cette raison que la capacité des niveaux précédents à fournir des réponses en amont représente un avantage déterminant.
Performance et évolutivité
L’un des bénéfices les plus sous-estimés de ce modèle réside dans le fait que tout n’a pas besoin d’être exécuté systématiquement. Dans la vision frontend-backend traditionnelle, une requête parcourt souvent une grande partie du système avant qu’un rejet ne soit envisagé. Dans le nouveau modèle, chaque niveau agit comme un filtre intentionnel, évaluant la pertinence de transmettre la requête à l’étape suivante. Il ne s’agit pas d’une simple optimisation, mais d’une propriété structurelle qui modifie profondément le comportement du système sous charge.
Dès la périphérie, des décisions peuvent être prises pour interrompre immédiatement une requête. L’authentification, l’autorisation et la limitation du trafic ne sont plus des préoccupations internes à l’application, mais des mécanismes préalables à toute consommation de ressources applicatives. Concrètement, cela signifie que les requêtes invalides, non autorisées ou abusives n’atteignent jamais les composants les plus coûteux du système.
Les mécanismes de mise en cache renforcent encore cette approche. Lorsqu’une réponse peut être fournie directement depuis une couche périphérique ou de service, sans solliciter les données persistantes, on économise à la fois du temps et de la capacité globale. Ce n’est pas seulement un gain de vitesse, mais aussi un facteur de stabilité : moins les ressources les plus lentes et les plus coûteuses sont sollicitées, mieux le système résiste aux pics de charge et aux situations exceptionnelles.
L’évolutivité cesse alors d’être unidimensionnelle. Le système peut être renforcé et étendu différemment selon les niveaux. La couche périphérique peut être mise à l’échelle pour absorber des volumes de requêtes plus élevés sans toucher à la logique applicative. La couche de service peut être étendue par des composants parallèles, permettant la répartition de charge et des mises à jour maîtrisées. La couche de données peut être optimisée indépendamment, sans impact direct sur le trafic utilisateur.
Cette évolutivité multidirectionnelle réduit la nécessité de composants individuels surdimensionnés. Plutôt qu’un backend unique qui enfle de manière incontrôlée, les responsabilités et la charge se répartissent naturellement. Le résultat est un système qui non seulement évolue mieux, mais se comporte également de façon plus prévisible à mesure que la charge augmente.
Responsabilités et sécurité
Lorsque les responsabilités sont clairement séparées, la sécurité devient une propriété intrinsèque de l’architecture. Dans le modèle traditionnel, la sécurité est souvent traitée comme une caractéristique de l’application : les vérifications sont effectuées là où la requête est finalement traitée. Cela permet à un trafic malveillant ou erroné de pénétrer profondément dans le système avant d’être stoppé.
Dans le modèle multicouche, cette dynamique s’inverse. Le trafic nuisible doit être identifié et bloqué le plus tôt possible. La couche périphérique ne joue pas seulement le rôle de portier, mais celui d’une ligne de défense active protégeant les couches internes. Cela réduit la charge sur la logique applicative et diminue le risque qu’une erreur ou une vulnérabilité isolée se transforme en incident majeur.
L’approche Zero Trust s’inscrit naturellement dans cette architecture. Elle n’est ni un ajout ni un choix idéologique, mais la conséquence logique d’un système où aucun niveau ne fait confiance implicitement à un autre. Chaque requête est évaluée dans son contexte, et les droits sont vérifiés là où ils ont le plus d’impact. Le système gagne ainsi en résilience, tant face aux attaques externes qu’aux défaillances internes.
La clarté des responsabilités bénéficie également à l’organisation. Lorsque chaque équipe sait de quel niveau elle est responsable, les problèmes peuvent être localisés et résolus plus rapidement. La sécurité cesse d’être une responsabilité diffuse et devient un élément ancré dans des structures et des rôles concrets.
Faiblesses et réalités
Il convient d’être clair : les architectures multicouches ne sont pas exemptes de difficultés. Elles introduisent davantage d’éléments mobiles, de nouvelles interfaces et une exigence accrue de compréhension globale. Des configurations erronées, des frontières mal définies ou des responsabilités floues peuvent engendrer des situations où les problèmes sont plus difficiles à détecter que dans des modèles plus simples.
La prise de décision précoce implique également des choix fondés sur un contexte limité. Une limitation de trafic trop agressive ou un cache mal configuré peut bloquer des requêtes légitimes ou fournir des réponses incorrectes. Ces risques sont bien réels et ne doivent pas être minimisés.
La différence avec le modèle traditionnel ne réside toutefois pas dans la disparition des problèmes, mais dans leur localisation et leur manifestation. Dans les systèmes multicouches, les problèmes sont souvent plus visibles et mieux circonscrits. Ils peuvent être rattachés à un niveau précis et corrigés sans devoir arrêter ou redémarrer l’ensemble du système. À long terme, cela rend le système plus facile à maîtriser, malgré sa complexité structurelle.
Conclusion
Le modèle frontend-backend n’est pas erroné, mais il est insuffisant pour décrire la réalité des systèmes modernes. Il constitue un excellent point de départ, mais un point d’arrivée médiocre. En analysant les systèmes à travers le prisme des couches et des responsabilités, on accède à une compréhension plus profonde et plus réaliste de la manière dont naissent réellement la performance, la sécurité et l’évolutivité.
Le frontend-backend n’est pas dépassé parce qu’il aurait échoué, mais parce qu’il a accompli sa mission. Il a été une étape nécessaire du développement. Aujourd’hui, face à des systèmes plus complexes et à des exigences accrues, il est temps de passer à une abstraction suivante – une abstraction qui n’élude pas la complexité du réel, mais la rend maîtrisable.
L’une des conséquences les plus inconfortables de ce modèle est qu’il remet en question la séparation conceptuelle traditionnelle entre frontend et backend. Lorsque le code frontend est livré par le serveur, il n’est pas une exception architecturale, mais fait partie du même flux de trafic que toute autre ressource. Il traverse la même pipeline de requêtes, est soumis aux mêmes mécanismes d’authentification, de mise en cache et de gestion du trafic, et fait l’objet des mêmes décisions en matière de sécurité et de performance que les autres réponses. Dans ce sens, le frontend n’est pas une couche indépendante, mais un artefact parmi d’autres produits par le serveur.
Cette vision suscite souvent une résistance, précisément parce qu’elle rend visible ce qui pouvait auparavant être ignoré. Lorsque le frontend est considéré comme partie intégrante du pipeline, son impact sur la performance et la sécurité devient inévitable. La distribution de code statique n’est pas une note de bas de page anodine, mais une opération génératrice de charge, qui peut être gérée efficacement à la périphérie du système ou, à l’inverse, consommer inutilement les ressources de la couche applicative. Elle devient également une question de sécurité : un code mal versionné, mal mis en cache ou excessivement exposé constitue un risque aussi réel qu’une réponse backend défectueuse.
Dans le nouveau modèle, cela n’est pas un problème, mais une intention. En intégrant le frontend dans la même structure que les autres réponses, il bénéficie des mêmes mécanismes de protection et d’optimisation. Le trafic malveillant ou erroné peut être stoppé avant d’atteindre la logique applicative, et les requêtes répétitives peuvent être servies sans solliciter les composants les plus coûteux du système. Le frontend conserve sa nature d’interface utilisateur, mais perd son statut d’exception architecturale – et c’est précisément ce qui rend le système plus rapide, plus sûr et plus honnête dans sa description.
Le modèle présenté dans cet article est volontairement maintenu à un niveau général et conceptuel. Il ne vise pas encore à guider une implémentation spécifique, mais à transformer la manière même de concevoir un système. Chacun des niveaux décrits porte ses propres responsabilités, risques et opportunités, et leur compréhension exige plus qu’une analyse superficielle. C’est pourquoi les articles à venir examineront ces niveaux un par un, calmement et séparément, afin d’en explorer plus en détail les rôles, les limites et les implications pratiques.
Dans ces prochains textes, le modèle conceptuel sera également ancré dans des exemples plus concrets. Du code, des conteneurs et des schémas d’implémentation simples serviront à illustrer la manière dont ces principes se traduisent dans la pratique, sans enfermer la réflexion dans des technologies particulières. L’objectif n’est pas de fournir une recette prête à l’emploi, mais de montrer comment les décisions architecturales se reflètent dans des systèmes réels.
En particulier, le sixième niveau, la Data Plane, est ici volontairement resté abstrait. Il ne s’agit pas d’un détail secondaire, mais d’un ensemble qui requiert son propre espace et son propre cadre de réflexion. Les articles suivants examineront également comment cet ensemble peut être techniquement structuré en un système cohérent, sans contraindre l’organisation à devenir un monolithe unique. L’unité structurelle et la décentralisation organisationnelle ne sont pas opposées ; elles constituent au contraire une tension centrale de l’architecture moderne. Comprendre cette tension est une condition préalable pour transformer ce modèle, d’un simple schéma, en un système réellement opérationnel.