El modelo frontend-backend ya no es suficiente para describir los sistemas modernos
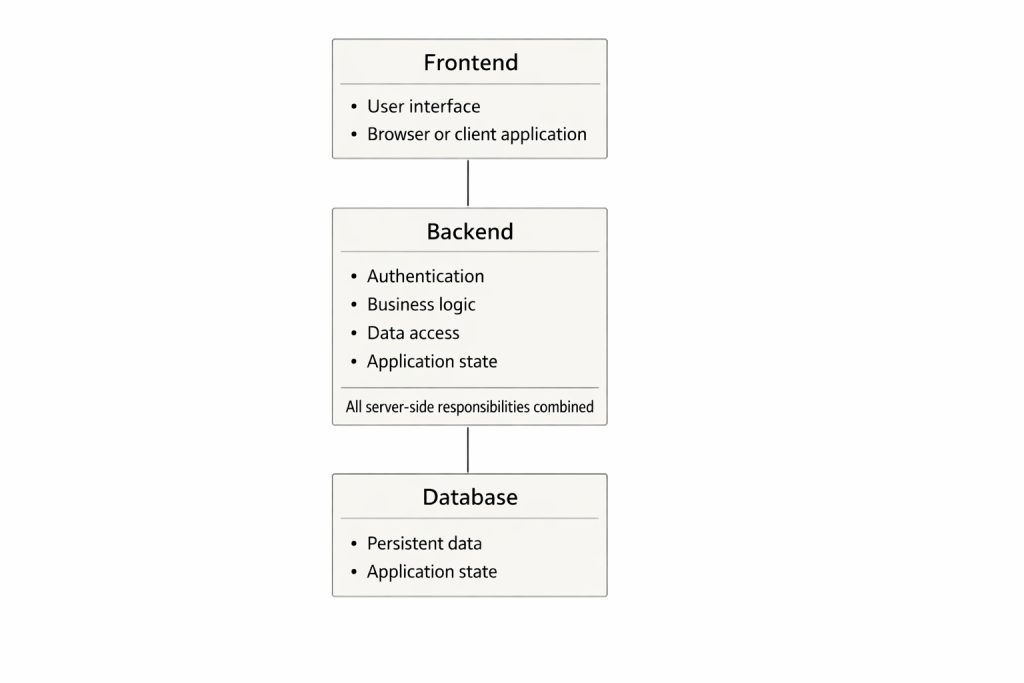
La división entre frontend y backend ha sido durante décadas uno de los principios fundamentales del desarrollo de software. Es simple, fácil de enseñar y pedagógicamente eficaz, razón por la cual sigue siendo ampliamente utilizada en universidades y programas de formación. La interfaz de usuario se sitúa al frente, el servidor detrás y la base de datos aún más al fondo. El usuario realiza una solicitud, el backend la procesa y devuelve una respuesta. El modelo es lógico e intuitivo, pero al mismo tiempo está cada vez más alejado de la realidad en la que operan los sistemas modernos.
Esto no significa que el pensamiento frontend-backend haya sido erróneo. Al contrario, fue una abstracción históricamente necesaria. El problema surge cuando se convierte en el punto final del razonamiento y no en su punto de partida. A medida que los sistemas crecen, el número de usuarios se multiplica y las exigencias de rendimiento, disponibilidad y seguridad se intensifican, un modelo de dos cajas deja de ser suficiente para describir la estructura real de un sistema, y mucho menos la distribución real de responsabilidades.
Origen histórico y sus límites
El modelo frontend-backend original surgió en una época en la que las aplicaciones solían ser monolíticas. Un único proceso de servidor contenía la autenticación, la lógica de negocio, la gestión del estado y el acceso a la base de datos. La interfaz de usuario era una capa delgada sobre ese núcleo. Todas las responsabilidades del lado del servidor estaban agrupadas en una sola entidad, y durante mucho tiempo esta fue una solución plenamente funcional.
En ese contexto, el rendimiento se mejoraba principalmente mediante el escalado vertical: más memoria, procesadores más rápidos, almacenamiento más eficiente. Escalar significaba utilizar una máquina más grande. La seguridad recaía en gran medida en la lógica de la aplicación, y la gestión del tráfico solía ocurrir en capas profundas del propio sistema. Este modelo sigue siendo válido para sistemas pequeños y casos de uso sencillos, y no debe ser subestimado.
Precisamente por eso resulta peligroso como base educativa si se mantiene durante demasiado tiempo. Transmite la idea de que el sistema es un único conducto en el que todo ocurre de forma secuencial y en el que cada solicitud recorre toda la cadena, independientemente de si ese recorrido es necesario o razonable.
La ampliación del pensamiento north-south
El modelo frontend-backend tradicional se basa casi exclusivamente en el tráfico north-south. La solicitud del usuario desciende por el sistema, se procesa y la respuesta asciende de nuevo. Esta forma de pensar era natural cuando los sistemas eran simples y la comunicación interna limitada.
A medida que los sistemas se distribuyeron y crecieron en complejidad, surgió la necesidad de separar el tráfico externo del tráfico interno. Los servicios comenzaron a comunicarse entre sí, los datos se sincronizaron en segundo plano y la coordinación interna pasó a representar una parte significativa de la carga total. En este punto, el tráfico east-west adquirió una importancia equivalente a la del tráfico tradicional orientado al usuario.
No se trató únicamente de un cambio técnico, sino de un cambio de mentalidad. El sistema dejó de ser un conducto lineal para convertirse en un ecosistema. No todo el tráfico tenía el mismo valor ni debía recorrer el mismo camino.
Una transformación arquitectónica
Cuando el tráfico north-south y east-west se distinguen entre sí, la estructura del sistema se transforma de manera fundamental. La arquitectura deja de organizarse alrededor de un único componente central y comienza a estratificarse de forma natural según las responsabilidades. El tráfico externo puede recibirse, interpretarse y, si es necesario, limitarse en el perímetro del sistema, antes de cargar la lógica de la aplicación o los datos persistentes. Al mismo tiempo, el tráfico interno puede optimizarse según otros criterios: fiabilidad, consistencia y observabilidad pasan a ocupar un lugar central.
Este cambio no es solo técnico, sino también conceptual. Cuando un sistema se entiende como un conjunto de flujos de tráfico interrelacionados, ya no necesita presentarse como un único “backend” homogéneo. Surge entonces un modelo multicapa en el que cada nivel tiene una función clara y una responsabilidad acotada. Ningún nivel intenta resolver el problema completo; cada uno aborda únicamente su parte. Esto reduce el acoplamiento interno y hace que el sistema sea más comprensible, no como una caja aislada, sino como un todo estructurado.
Desde la perspectiva del usuario, este cambio suele ser imperceptible. El usuario ya no interactúa con “el backend”, sino con múltiples capas del sistema, aunque esto no se refleje en la interfaz. La solicitud avanza paso a paso, y cada nivel toma su propia decisión sobre si la solicitud debe continuar. En este sentido, el sistema se asemeja más a un proceso deliberativo que a un conducto directo.
Esta deliberación es precisamente el núcleo del modelo multicapa. Cada nivel realiza menos tareas que un backend tradicional, pero las ejecuta de forma más consciente y controlada. Las responsabilidades no desaparecen; se trasladan a los lugares donde pueden gestionarse con mayor eficacia. La arquitectura no se vuelve compleja porque se añadan capas arbitrariamente, sino porque la realidad misma es compleja. La estratificación es una forma de hacer visible esa complejidad y, por tanto, de hacerla manejable.
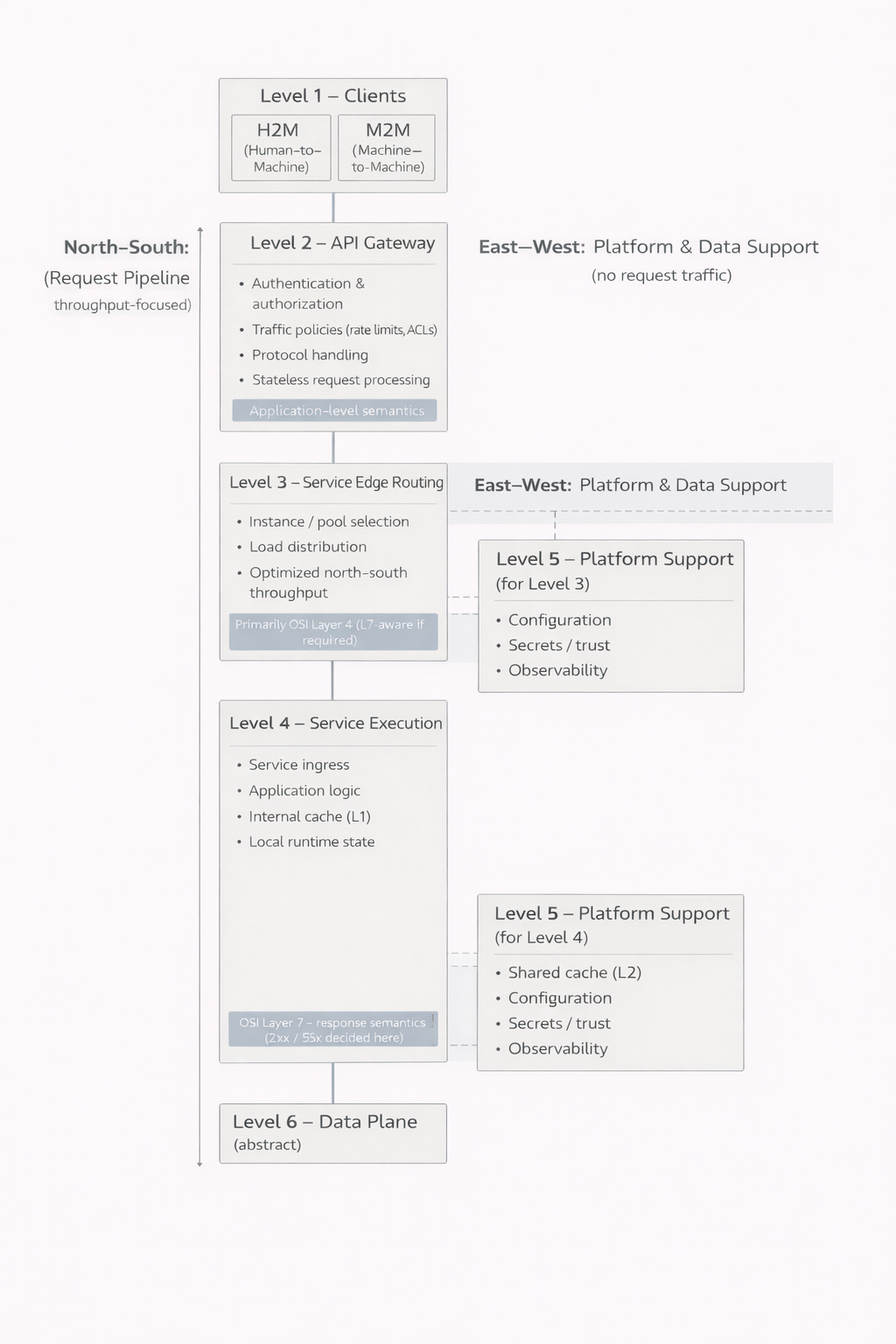
Los niveles 1-6 como conjunto
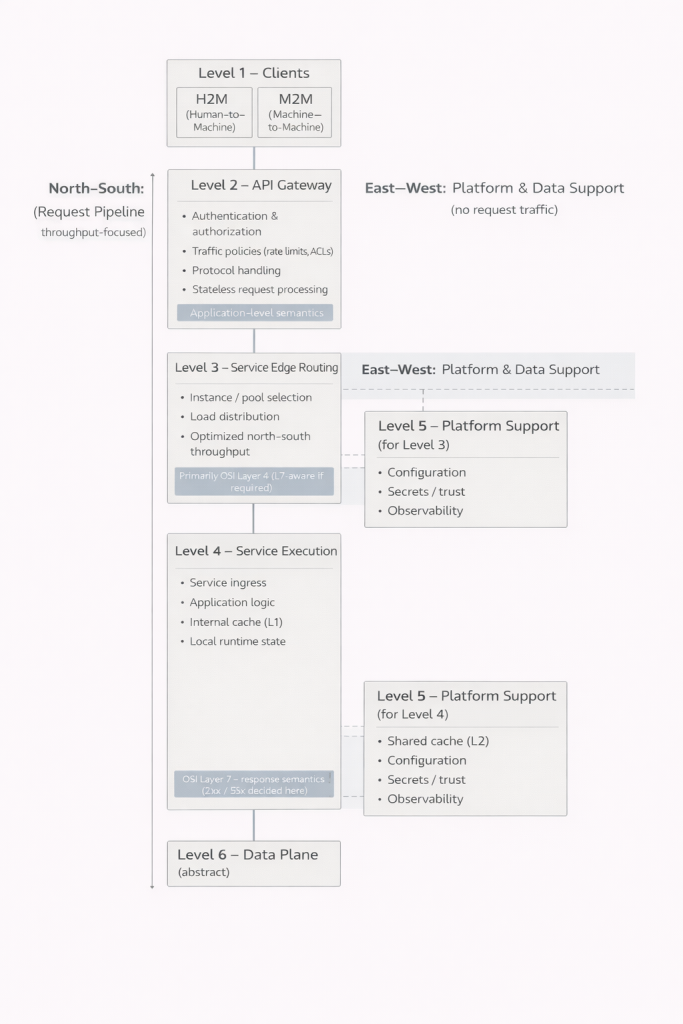
El primer nivel corresponde a los clientes. Las interfaces utilizadas por personas y las integraciones entre máquinas pueden parecer similares desde el exterior, pero sus requisitos y comportamientos pueden ser radicalmente distintos. Reconocer esta diferencia es esencial, ya que el sistema debe ser capaz de atender a ambos de forma controlada.
El segundo nivel constituye la frontera entre el sistema y el mundo exterior. Aquí se realizan la autenticación, la autorización, la limitación del tráfico y, con frecuencia, la gestión de protocolos. Un aspecto clave es que no todas las solicitudes avanzan más allá de este punto. Credenciales inválidas, permisos insuficientes o límites superados pueden rechazarse de inmediato. Esto reduce la carga sobre los niveles más profundos del sistema y mejora tanto el rendimiento como la seguridad.
El tercer nivel se encarga de dirigir el tráfico hacia los servicios correspondientes. En sistemas pequeños, este nivel puede integrarse en el siguiente y no siempre se identifica como una entidad independiente. Sin embargo, cuando crecen el número de usuarios y de instancias, se vuelve indispensable. Permite la distribución de carga, el aislamiento de fallos y un escalado controlado.
El cuarto nivel es donde se realiza el trabajo real de la aplicación. Aquí tienen lugar la lógica de negocio, la construcción de las respuestas y la gestión del estado local. Es importante entender que este nivel no es necesariamente un único bloque. Puede estar compuesto por varios componentes paralelos que sirven a un mismo propósito. Esto permite actualizar o retirar partes individuales sin interrumpir el servicio completo. El usuario puede no percibir nada, incluso cuando se producen cambios significativos dentro del sistema.
El quinto nivel introduce el control operativo. Configuraciones, relaciones de confianza, secretos y observabilidad no forman parte de la lógica de negocio, pero son imprescindibles para operar el sistema de forma segura y fiable. En sistemas pequeños, estas responsabilidades suelen estar ocultas e integradas en otros componentes. A medida que el sistema crece, emergen inevitablemente como preocupaciones independientes.
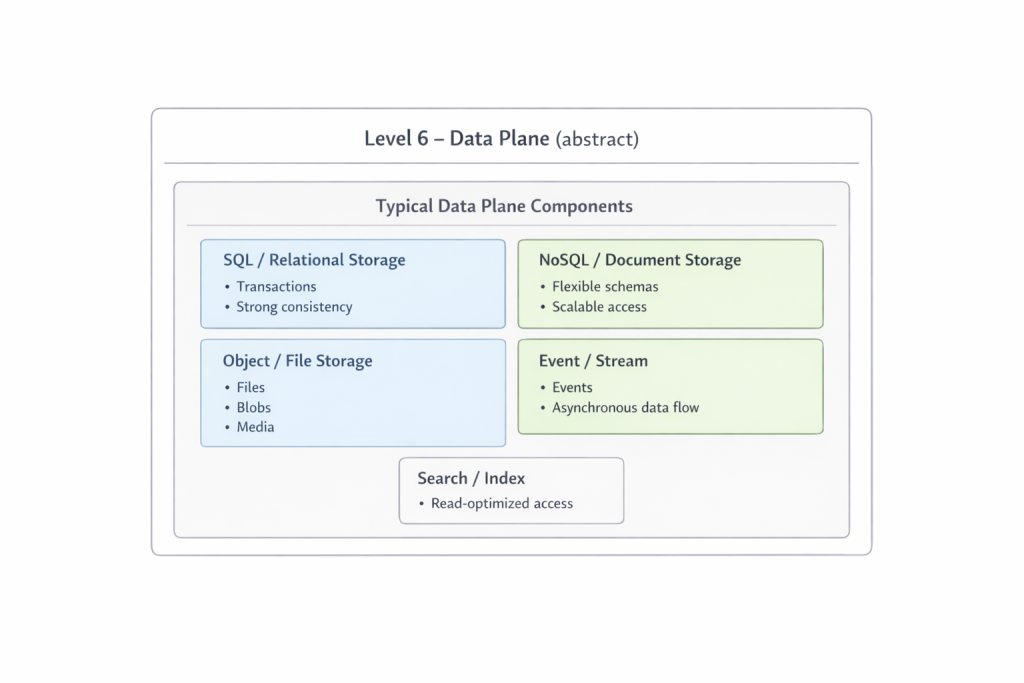
El sexto nivel es el dominio de los datos. Se mantiene deliberadamente abstracto, ya que merece un análisis propio. Archivos, relaciones, eventos y flujos constituyen la base sobre la que se apoya todo lo demás. Cuanto más profundo avanza una solicitud en este nivel, más costosa y lenta suele volverse. Precisamente por eso, la capacidad de los niveles anteriores para devolver respuestas antes representa una ventaja tan significativa.
Rendimiento y escalabilidad
Quizá el beneficio más infravalorado de este modelo sea que no todo tiene que ejecutarse siempre. En el pensamiento frontend-backend tradicional, una solicitud suele recorrer gran parte del sistema antes de que siquiera se considere su rechazo. En el nuevo modelo, cada nivel actúa como un filtro deliberado que evalúa si tiene sentido que la solicitud continúe hacia la siguiente etapa. Esto no es solo una optimización del rendimiento, sino una propiedad estructural que cambia de forma fundamental el comportamiento del sistema bajo carga.
En el perímetro del sistema ya pueden tomarse decisiones que interrumpen una solicitud de inmediato. La autenticación, la autorización y la limitación del tráfico dejan de ser preocupaciones internas de la aplicación y pasan a ser pasos previos al consumo de cualquier recurso de la lógica de negocio. En la práctica, esto significa que las solicitudes inválidas, no autorizadas o abusivas nunca alcanzan las partes más costosas del sistema.
Los mecanismos de caché refuerzan aún más este principio. Cuando una respuesta puede servirse directamente desde una capa perimetral o de servicio sin acceder a datos persistentes, se ahorra tiempo y capacidad global del sistema. No se trata solo de velocidad, sino también de estabilidad: cuanto menos se utilizan los recursos más lentos y caros, mejor resiste el sistema los picos de carga y las situaciones excepcionales.
La escalabilidad deja de ser unidimensional. El sistema puede ampliarse y fortalecerse de distintas maneras en diferentes niveles. La capa perimetral puede escalarse para manejar mayores volúmenes de solicitudes sin tocar la lógica de la aplicación. La capa de servicio puede ampliarse mediante componentes paralelos que compartan la carga y permitan actualizaciones controladas. La capa de datos puede optimizarse de forma independiente, sin afectar directamente al tráfico de los usuarios.
Esta escalabilidad multidireccional reduce la necesidad de componentes individuales sobredimensionados. En lugar de un backend único que crece sin control, las responsabilidades y la carga se distribuyen de manera natural. El resultado es un sistema que no solo escala mejor, sino que también se comporta de forma más predecible a medida que aumenta la carga.
Responsabilidades y seguridad
Cuando las responsabilidades se separan con claridad, la seguridad se convierte en una propiedad inherente de la arquitectura. En el modelo tradicional, la seguridad suele tratarse como una característica de la aplicación: las comprobaciones se realizan allí donde la solicitud finalmente se procesa. Esto permite que tráfico malicioso o erróneo penetre profundamente en el sistema antes de ser detenido.
En el modelo multicapa, esta dinámica se invierte. El tráfico dañino se identifica y bloquea lo antes posible. La capa perimetral no actúa solo como un portero, sino como una línea de defensa activa que protege las capas internas. Esto reduce la carga sobre la lógica de la aplicación y disminuye el riesgo de que un fallo o vulnerabilidad aislada se convierta en un problema generalizado.
El enfoque Zero Trust encaja de forma natural en esta arquitectura. No es un añadido ni una postura ideológica, sino la consecuencia lógica de un sistema en el que ningún nivel confía implícitamente en otro. Cada solicitud se evalúa en su contexto, y los permisos se verifican donde tienen mayor impacto. Esto hace que el sistema sea más resistente tanto a ataques externos como a fallos internos.
La claridad en la asignación de responsabilidades también aporta beneficios a nivel organizativo. Cuando se sabe qué equipo es responsable de cada nivel, los problemas pueden localizarse y resolverse con mayor rapidez. La seguridad deja de ser una responsabilidad difusa y pasa a estar vinculada a estructuras y roles concretos.
Debilidades y realidades
Es importante reconocer que las arquitecturas multicapa no están exentas de inconvenientes. Introducen más elementos en movimiento, nuevas interfaces y una mayor necesidad de comprender el sistema como un todo. Configuraciones incorrectas, límites mal definidos o responsabilidades poco claras pueden dar lugar a situaciones en las que los problemas son más difíciles de detectar que en modelos más simples.
La toma de decisiones temprana implica inevitablemente decisiones basadas en un contexto limitado. Una limitación de tráfico demasiado agresiva o una caché mal configurada puede bloquear tráfico legítimo o devolver datos incorrectos. Estos riesgos son reales y no deben minimizarse.
La diferencia con el modelo tradicional no radica en que los problemas desaparezcan, sino en dónde y cómo se manifiestan. En los sistemas multicapa, los problemas suelen ser más visibles y estar mejor acotados. Pueden asociarse a un nivel concreto y corregirse sin necesidad de detener o reiniciar todo el sistema. A largo plazo, esto hace que el sistema sea más fácil de operar, a pesar de su complejidad estructural.
Conclusión
El modelo frontend-backend no es incorrecto, pero es insuficiente para describir la realidad de los sistemas modernos. Funciona como un excelente punto de partida, pero como un pobre punto de llegada. Al analizar los sistemas en términos de capas y responsabilidades, se obtiene una comprensión más profunda y realista de cómo se logran realmente el rendimiento, la seguridad y la escalabilidad.
El frontend-backend no ha quedado obsoleto porque haya fracasado, sino porque ha cumplido su función. Ha sido un paso necesario en la evolución de la arquitectura de software. Hoy, con sistemas más complejos y exigencias más elevadas, es momento de avanzar hacia la siguiente abstracción: una que no rehúya la complejidad de la realidad, sino que la haga manejable.
Una de las consecuencias más incómodas de este modelo es que también rompe conceptualmente la separación tradicional entre frontend y backend. Cuando el código frontend se entrega desde el servidor, no es una excepción arquitectónica, sino parte del mismo flujo de tráfico que cualquier otro recurso. Recorre la misma canalización de solicitudes, está sujeto a los mismos mecanismos de autenticación, caché y control de tráfico, y se ve afectado por las mismas decisiones de seguridad y rendimiento que cualquier otra respuesta. En este sentido, el frontend no es una capa independiente, sino uno más de los artefactos producidos por el servidor.
Esta idea suele generar resistencia precisamente porque hace visible lo que antes podía ignorarse. Cuando el frontend se trata como parte del mismo conducto, su impacto en el rendimiento y la seguridad se vuelve ineludible. La entrega de código estático no es una nota al margen sin coste, sino una operación que genera carga y que puede gestionarse eficientemente en el perímetro del sistema o, por el contrario, consumir innecesariamente recursos de la capa de aplicación. Al mismo tiempo, la entrega del frontend se convierte en una cuestión de seguridad: un código mal versionado, mal almacenado en caché o excesivamente expuesto supone un riesgo tan real como una respuesta backend defectuosa.
En el nuevo modelo, esto no es un problema, sino el objetivo. Al integrar el frontend en la misma estructura que el resto de las respuestas, se beneficia de los mismos mecanismos de protección y optimización. El tráfico malicioso o erróneo puede detenerse antes de alcanzar la lógica de la aplicación, y las solicitudes repetidas pueden resolverse sin tocar los componentes más costosos del sistema. El frontend no pierde su función como interfaz de usuario, pero pierde su inmunidad arquitectónica, y precisamente eso es lo que hace que el sistema sea más rápido, más seguro y más honesto de describir.
El modelo presentado en este artículo se mantiene deliberadamente en un nivel general y conceptual. Su propósito no es aún prescribir una implementación concreta, sino cambiar la forma en que se conciben los sistemas desde su base. Cada uno de los niveles descritos conlleva sus propias responsabilidades, riesgos y oportunidades, y comprenderlos requiere algo más que un análisis superficial. Por ello, los artículos futuros examinarán estos niveles uno a uno, de forma pausada y separada, desglosando con mayor detalle sus funciones, límites e implicaciones prácticas.
En esos textos posteriores, el modelo conceptual se anclará también en ejemplos más concretos. Se utilizarán código, contenedores y patrones de implementación sencillos para ilustrar cómo estos principios se manifiestan en la práctica, sin centrar la atención en tecnologías específicas. El objetivo no es proporcionar una receta cerrada, sino mostrar cómo las decisiones arquitectónicas se reflejan en sistemas reales.
En particular, el sexto nivel, la denominada Data Plane, se ha dejado aquí de forma intencionadamente abstracta. No es un detalle secundario, sino un ámbito que requiere su propio espacio y su propio marco conceptual. En artículos posteriores se analizará cómo este conjunto puede estructurarse técnicamente como un sistema coherente sin obligar a la organización a convertirse en un único monolito. La coherencia estructural y la descentralización organizativa no son opuestas, sino una tensión central de la arquitectura moderna. Comprender esta tensión es un requisito previo para transformar este modelo, de un diagrama, en un sistema que funcione realmente.