Frontend-backend is no longer sufficient to describe modern systems
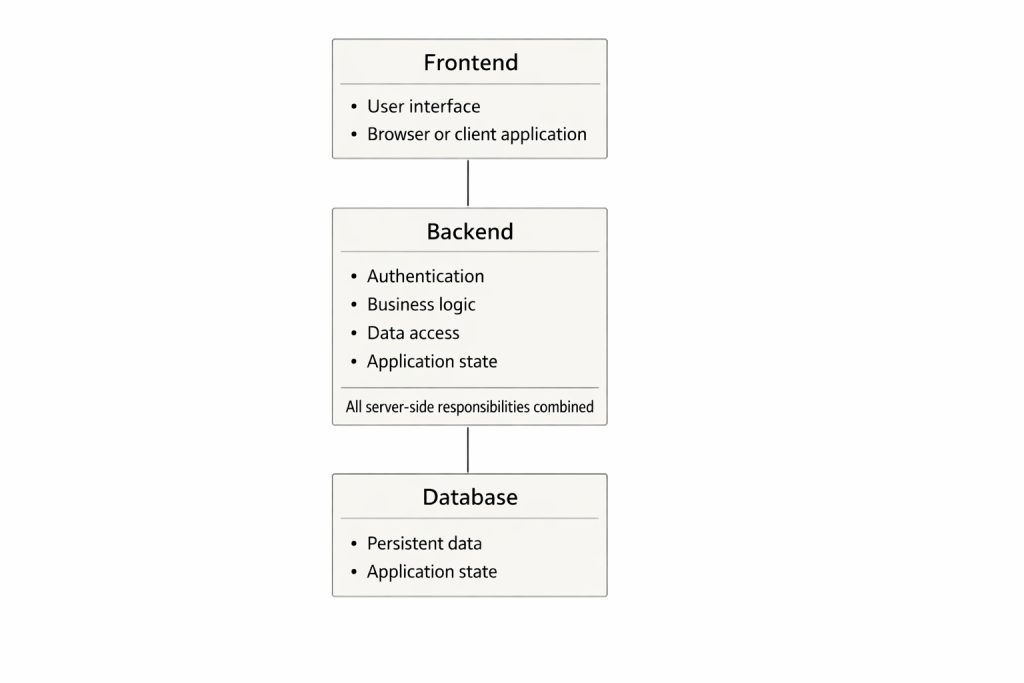
The frontend-backend split has been a foundational concept in software engineering for decades. It is simple, easy to teach, and pedagogically effective, which is precisely why it continues to be taught widely in universities and training programs. The user interface sits in front, the server behind it, and the database further back still. A user makes a request, the backend processes it, and a response is returned. The model is logical and intuitive – yet at the same time, increasingly detached from the reality in which modern systems actually operate.
This does not mean that frontend-backend thinking was wrong. On the contrary, it was a historically necessary abstraction. The problem only arises when it becomes the end point of thinking rather than its starting point. As systems grow, user numbers multiply, and requirements for performance, availability, and security become stricter, a two-box model is no longer sufficient to describe the real structure of a system – let alone the real distribution of responsibility within it.
Historical foundations and their limits
The original frontend-backend model emerged at a time when applications were often monolithic. A single server process contained authentication, business logic, state management, and database access. The user interface was a thin layer on top of this core. All server-side responsibilities were bundled into a single unit, and for a long time, this was a perfectly workable solution.
In this world, performance improvements were achieved primarily through vertical scaling: more memory, faster CPUs, better disks. Scaling meant a larger machine. Security was largely handled inside application logic, and traffic control typically occurred deep within the application itself. This model still works for small systems and simple use cases, and it should not be dismissed outright.
Precisely because of this, however, it is also dangerous as a long-term educational baseline. It creates the impression that a system is a single pipeline in which everything happens sequentially, and where every request travels through the entire chain regardless of whether that journey is necessary or even sensible.
The expansion of north–south thinking
The traditional frontend-backend model is built almost entirely around north-south traffic. A user request flows downward, the system processes it, and the response flows back up. This way of thinking was natural in an era when systems were relatively simple and internal communication was minimal.
As systems became more distributed and more complex, the need to separate external traffic from internal traffic became unavoidable. Services began communicating with one another, data was synchronized in the background, and internal coordination became a significant part of the overall load. At this point, east–west traffic became just as central as traditional user-driven traffic.
This was not merely a technical shift, but a conceptual one. The system was no longer a pipeline, but an ecosystem. Not all traffic was equal, and not all traffic belonged on the same path.
An architectural shift
When north-south and east-west traffic are treated as distinct concerns, something fundamental changes in the structure of the system. Architecture no longer organizes itself around a single central component, but begins to layer naturally according to responsibility. External traffic can be received, interpreted, and, if necessary, constrained at the edge of the system, before it burdens application logic or persistent data. Internal traffic, in turn, is freed to optimize for different goals: reliability, consistency, and observability move to the forefront.
This shift is not only technical, but conceptual. When a system is understood as a set of interacting traffic flows, it no longer needs to pretend that it is a single, unified “backend.” Instead, a layered model emerges in which each level has a clear role and a bounded responsibility. No single layer attempts to solve the entire problem; each addresses only its own part. This reduces internal coupling and makes the system easier to reason about – not as a single box, but as an organized whole.
From the user’s perspective, this change is often invisible. The user no longer interacts with “the backend,” but with multiple layers of the system, even though this is not reflected in the user interface. The request progresses step by step, and each layer makes its own decision about whether the request should proceed further at all. In this sense, the system begins to resemble a deliberative process rather than a straight-through pipeline.
This deliberateness is the core of the layered model. Each layer does fewer things than a traditional backend, but does them more consciously and in a more controlled manner. Responsibilities do not disappear; they move to places where they can be carried more effectively. Architecture becomes more complex not because layers are added arbitrarily, but because reality itself is complex. Layering is a way to make that complexity visible – and therefore manageable.
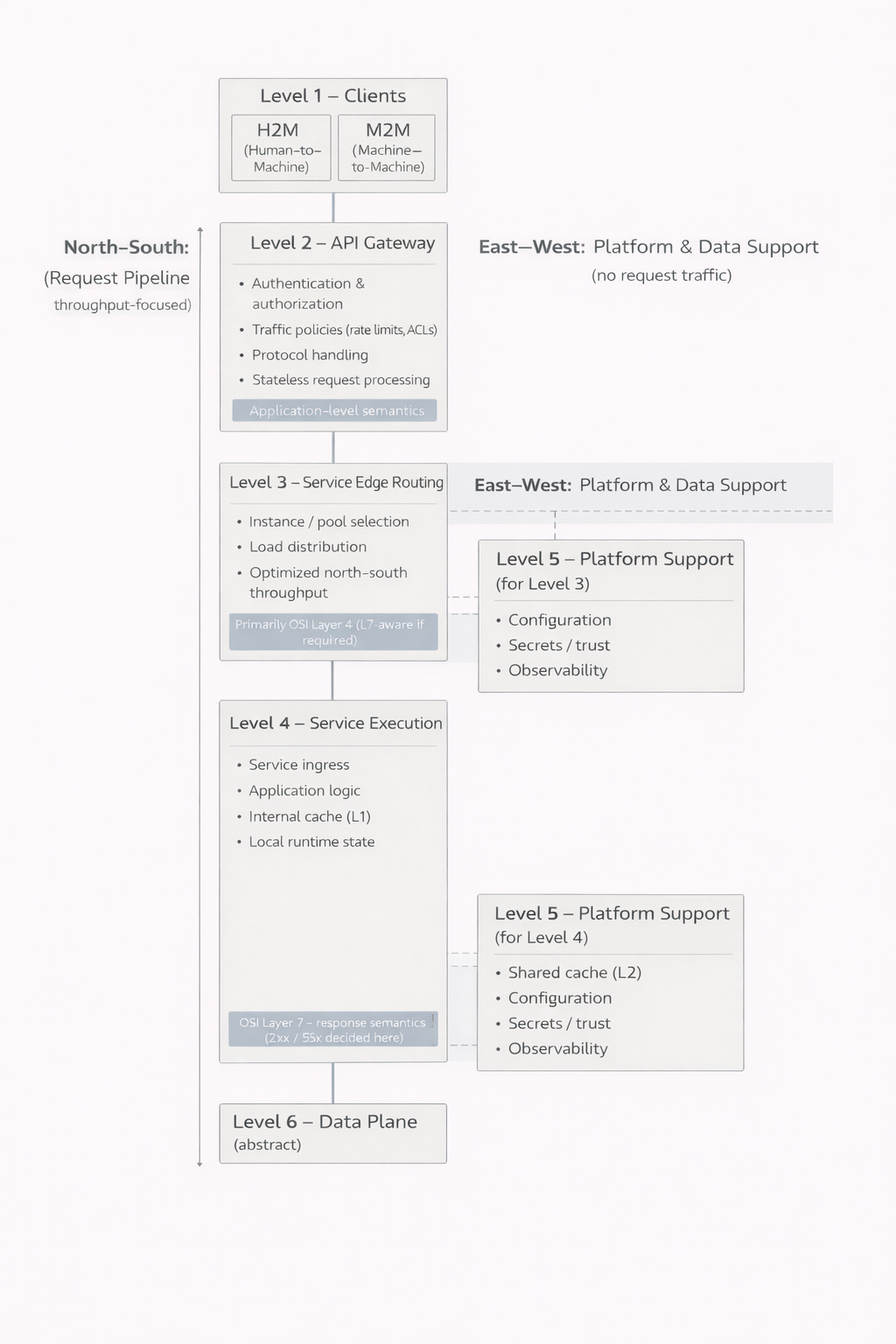
Levels 1–6 as a whole
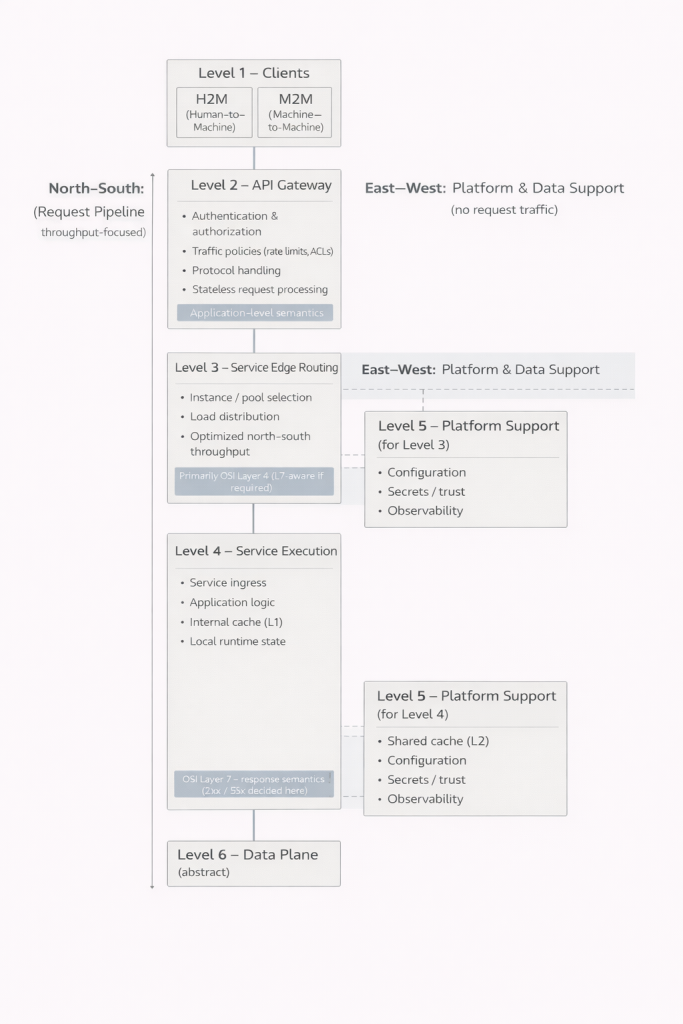
The first level consists of clients. Human-facing user interfaces and machine-to-machine integrations may look similar from the outside, but their requirements and behavior can be fundamentally different. Recognizing this distinction is essential, because the system must be able to serve both in a controlled way.
The second level forms the boundary between the system and the outside world. Authentication, authorization, traffic limiting, and often protocol handling take place here. A crucial observation is that not all requests proceed beyond this point. Invalid credentials, insufficient permissions, or exceeded limits can be rejected immediately. This reduces load on deeper layers of the system and improves both performance and security.
The third level is responsible for directing traffic to services. In small systems, this layer may be merged into the next one and not explicitly recognized. As user numbers grow and instance counts increase, however, it becomes indispensable. It enables load distribution, fault isolation, and controlled scaling.
The fourth level is where the application’s actual work is done. Business logic, response construction, and local state management occur here. It is important to understand that this level is not a single block. It can consist of multiple parallel components serving the same overall function. This allows individual parts to be updated or taken offline while others continue serving traffic. The user may notice nothing, even while significant changes are taking place inside the system.
The fifth level introduces operational control. Configuration, trust relationships, secrets, and observability are not application logic, but without them the system cannot be operated safely or reliably. In small systems, these responsibilities are often hidden and baked into other components. As the system grows, they inevitably emerge as distinct concerns.
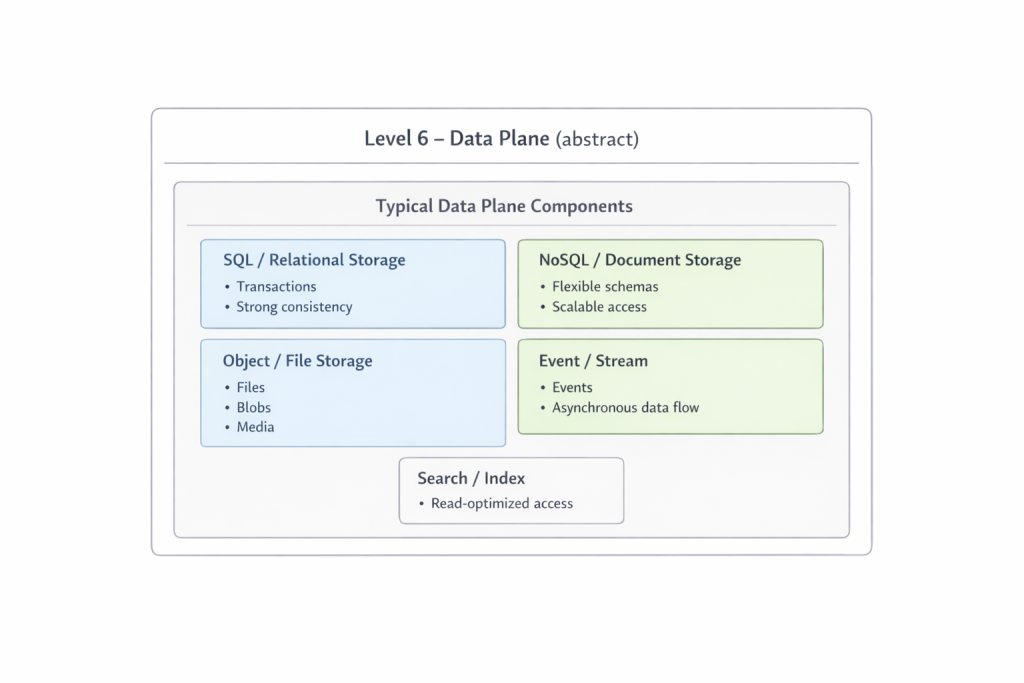
The sixth level is the domain of data. It is intentionally kept abstract here, because it deserves its own examination. Files, relations, events, and streams form the foundation upon which everything else rests. The deeper a request progresses into this level, the more expensive and slower it generally becomes. This is precisely why the ability of earlier layers to return responses sooner is such a significant advantage.
Performance and scalability
Perhaps the most underestimated benefit of this model is that not everything always has to happen. In traditional frontend-backend thinking, a request often travels deep into the system before rejection is even considered. In the new model, each layer acts as a deliberate filter, assessing whether it makes sense for the request to proceed to the next stage at all. This is not merely performance optimization, but a structural property that fundamentally changes how the system behaves under load.
Decisions can be made at the very edge of the system that terminate a request immediately. Authentication, authorization, and traffic limiting are no longer concerns handled inside application instances, but steps that occur before any application-level resources are consumed. In practice, this means that invalid, unauthorized, or abusive requests never reach the most expensive parts of the system.
Caching reinforces this principle further. When a response can be served directly from an edge or service-level cache without touching persistent data, time is saved and overall system capacity is preserved. This is not only about speed, but about stability: the less frequently the most expensive and slowest resources are accessed, the better the system withstands spikes and exceptional conditions.
Scalability in this model is no longer one-dimensional. The system can be expanded and strengthened at different layers in different ways. The edge can be scaled to handle higher request volumes without touching application logic. Service execution can be expanded through parallel components that share load and enable controlled updates. The data layer can be optimized independently, without directly impacting user-facing traffic.
This multidirectional scalability reduces the need for oversized individual components. Instead of a single backend growing uncontrollably, responsibilities and load distribute naturally. The result is a system that not only scales better, but behaves more predictably as load increases.
Responsibility and security
When responsibilities are clearly separated, security becomes a natural property of the structure. In the traditional model, security is often an application feature: checks are performed where the request is ultimately handled. This means that malicious or malformed traffic often penetrates deep into the system before being stopped.
In a layered model, this dynamic is reversed. Harmful traffic is identified and blocked as early as possible. The edge is not merely a gatekeeper, but an active defensive layer that protects deeper parts of the system. This reduces the burden on application logic and lowers the risk that a single flaw or vulnerability escalates into a widespread failure.
Zero Trust thinking fits naturally into this architecture. It is not an add-on or an ideological stance, but a logical consequence of a system in which no layer implicitly trusts another. Each request is evaluated in context, and permissions are verified where they matter most. This makes the system more resilient to both external attacks and internal failures.
Clear responsibility boundaries also help at the organizational level. When it is known which team is responsible for which layer, problems can be located and resolved more quickly. Security does not remain a vague shared concern, but is tied to concrete structures and roles.
Weaknesses and realities
It must be stated plainly that layered architectures are not without cost. They introduce more moving parts, more interfaces, and a greater need to understand the system as a whole. Misconfigurations, poorly defined boundaries, or unclear responsibilities can create situations where problems are harder to detect than in simpler models.
Early decision-making also inevitably means making decisions with limited context. Aggressive traffic limiting or incorrectly configured caches can block legitimate traffic or serve incorrect data. These risks are real and should not be downplayed.
The difference from traditional models is not that problems disappear, but where and how they manifest. In layered systems, issues are often more visible and more contained. They can be traced to specific layers and corrected without shutting down or restarting the entire system. In the long run, this makes the system easier to operate, even though it is structurally more complex.
Closing remarks
The frontend-backend model is not wrong, but it is insufficient to describe the reality of modern systems. It works well as a starting point, but poorly as an endpoint. When systems are examined in terms of layers and responsibilities, a deeper and more realistic understanding emerges of how performance, security, and scalability are actually achieved.
Frontend–backend is not obsolete because it failed, but because it succeeded. It fulfilled its role as a necessary step in the evolution of software architecture. Now that systems are more complex and demands more severe, it is time to move to the next abstraction – one that does not shy away from complexity, but makes it manageable.
One of the more uncomfortable consequences of this model is that it also breaks the traditional frontend-backend divide conceptually. When frontend code is delivered from a server, it is not an architectural exception, but part of the same traffic flow as any other resource. It passes through the same request pipeline, is subject to the same authentication, caching, and traffic control, and is exposed to the same security and performance decisions as any other response. In this sense, frontend is not a separate layer, but one server-produced artifact among many.
This idea is unsettling precisely because it exposes what could previously be ignored. When frontend is treated as part of the same pipeline, its impact on performance and security becomes unavoidable. Serving static code is not a free side note, but a load-generating operation that can either be handled efficiently at the edge or allowed to consume application-layer resources unnecessarily. At the same time, frontend delivery becomes a security concern: incorrectly versioned, poorly cached, or overly permissive frontend code is as much a risk as any faulty backend response.
In the new model, this is not a problem, but the point. When frontend is brought into the same structure as other responses, it benefits from the same protective mechanisms and optimizations. Harmful or malformed traffic can be stopped before it reaches application logic, and repeated resource requests can be served without touching the system’s most expensive components. Frontend has not lost its role as a user interface, but it has lost its architectural immunity – and that is precisely what makes the system faster, safer, and more honest to describe.
The model presented in this article is intentionally kept at a conceptual level. Its purpose is not yet to prescribe a specific implementation, but to change how systems are understood in the first place. Each described layer carries its own responsibilities, risks, and opportunities, and understanding them cannot be achieved through superficial analysis. For this reason, future articles will examine these layers one by one, in isolation and in depth, unpacking their roles, boundaries, and practical implications.
In those future texts, the conceptual model will also be anchored in more concrete examples. Code, containers, and simple implementation patterns will be used to illustrate how the same principles appear in practice, without shifting the focus to specific technologies. The goal is not to present a ready-made recipe, but to show how architectural decisions are reflected in real systems.
The sixth level, the so-called Data Plane, has been intentionally left abstract here. This is not a footnote, but a domain that requires its own space and its own conceptual framework. Future articles will explore how this entire structure can be built into a coherent technical system without forcing an organization into a single monolith. Structural coherence and administrative decentralization are not opposites, but a central tension of modern architecture. Understanding this tension is a prerequisite for turning the model from a diagram into a functioning system.