Frontend-Backend reicht nicht mehr aus, um moderne Systeme zu beschreiben
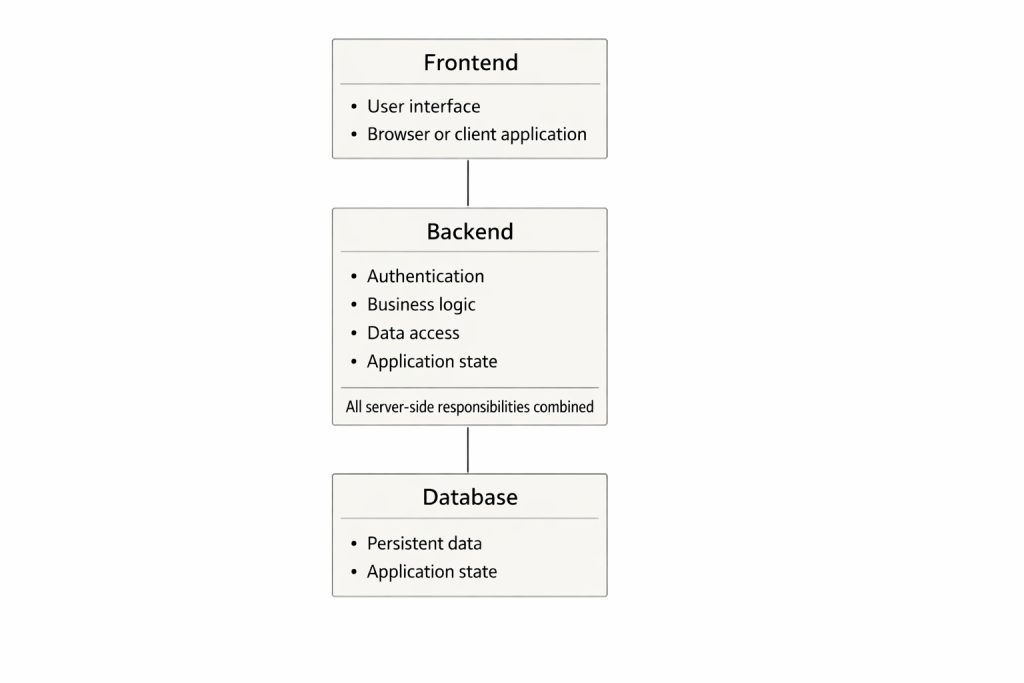
Die Trennung von Frontend und Backend gehört seit Jahrzehnten zu den Grundpfeilern der Softwareentwicklung. Sie ist einfach, gut vermittelbar und didaktisch wirkungsvoll – genau deshalb wird sie bis heute in Hochschulen und Ausbildungsprogrammen breit gelehrt. Die Benutzeroberfläche befindet sich vorne, der Server dahinter, und die Datenbank noch weiter im Hintergrund. Der Nutzer stellt eine Anfrage, das Backend verarbeitet sie und liefert eine Antwort zurück. Dieses Modell ist logisch und intuitiv – zugleich aber zunehmend weit entfernt von der Realität, in der moderne Systeme tatsächlich operieren.
Das bedeutet nicht, dass das Frontend-Backend-Denken falsch gewesen wäre. Im Gegenteil: Es war eine historisch notwendige Abstraktion. Das Problem entsteht erst dann, wenn sie zum Endpunkt des Denkens wird und nicht mehr als Ausgangspunkt dient. Wenn Systeme wachsen, Nutzerzahlen sich vervielfachen und die Anforderungen an Performance, Verfügbarkeit und Sicherheit steigen, reicht ein Zwei-Boxen-Modell nicht mehr aus, um die reale Struktur eines Systems zu beschreiben – und schon gar nicht die tatsächlichen Verantwortlichkeiten innerhalb desselben.
Historische Ausgangslage und ihre Grenzen
Das ursprüngliche Frontend-Backend-Modell entstand in einer Zeit, in der Anwendungen häufig monolithisch aufgebaut waren. Ein einzelner Serverprozess umfasste Authentifizierung, Geschäftslogik, Zustandsverwaltung und Datenbankzugriffe. Die Benutzeroberfläche bildete eine dünne Schicht darüber. Sämtliche serverseitigen Verantwortlichkeiten waren in einer einzigen Einheit gebündelt, und über lange Zeit hinweg war dies eine vollkommen funktionierende Lösung.
In dieser Welt wurde Performance vor allem vertikal verbessert: mehr Arbeitsspeicher, schnellere Prozessoren, leistungsfähigere Speichermedien. Skalierung bedeutete ein größeres System. Sicherheit war größtenteils Aufgabe der Anwendungslogik, und Verkehrssteuerung fand häufig erst tief innerhalb der Anwendung statt. Dieses Modell funktioniert nach wie vor für kleine Systeme und einfache Anwendungsfälle und sollte nicht geringgeschätzt werden.
Gerade deshalb ist es jedoch als langfristige didaktische Grundlage problematisch, wenn man zu lange an ihm festhält. Es vermittelt das Bild eines Systems als lineare Pipeline, in der alles sequenziell abläuft und jede Anfrage den gesamten Weg durchlaufen muss – unabhängig davon, ob dies notwendig oder sinnvoll ist.
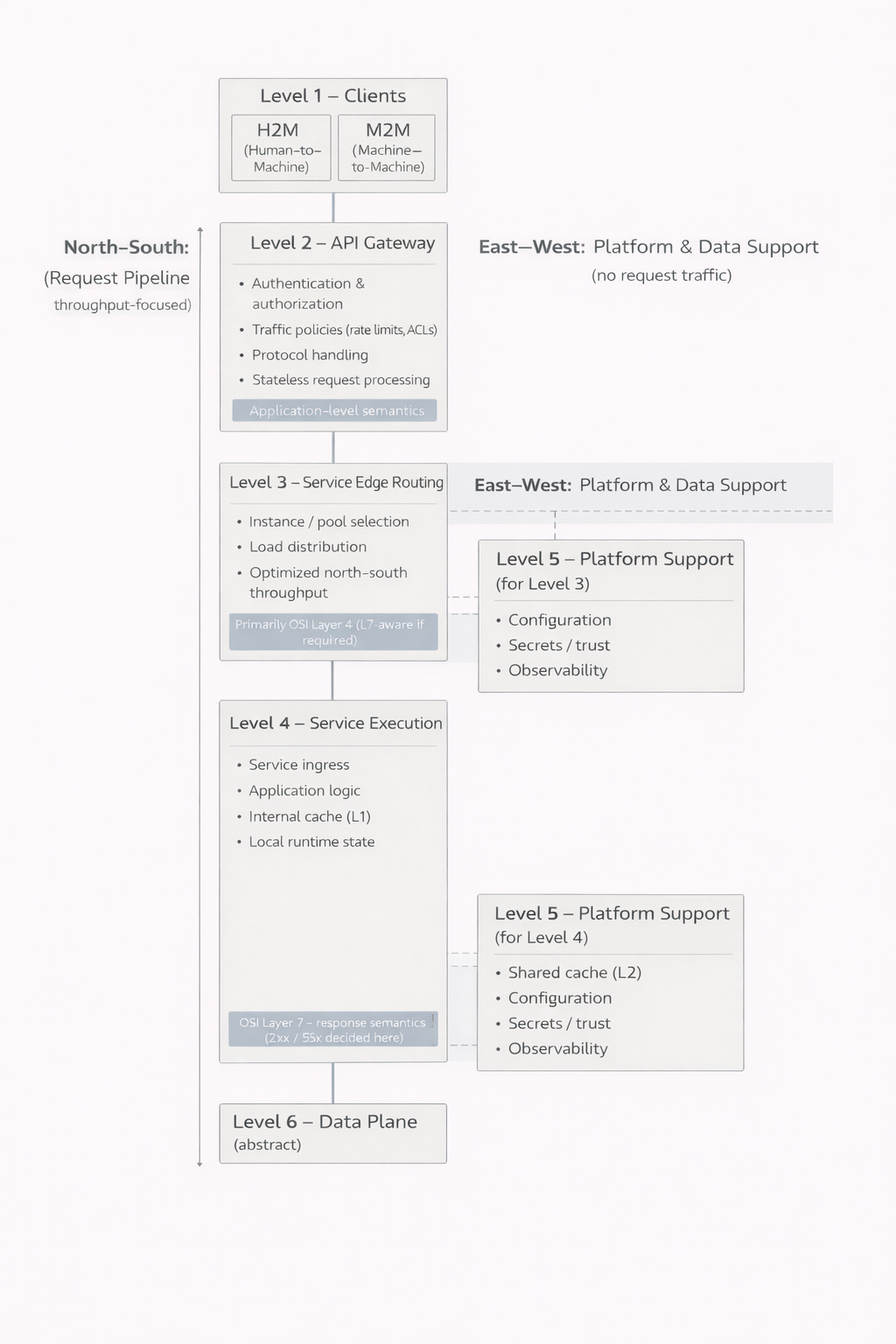
Die Erweiterung des North-South-Denkens
Das klassische Frontend-Backend-Modell basiert nahezu ausschließlich auf North-South-Verkehr. Eine Nutzeranfrage fließt von oben nach unten, das System verarbeitet sie und sendet eine Antwort zurück. Diese Denkweise war naheliegend in einer Zeit, in der Systeme überschaubar und interne Kommunikation gering war.
Mit der zunehmenden Verteilung und Komplexität von Systemen entstand jedoch die Notwendigkeit, externen Verkehr von internem Verkehr zu trennen. Dienste begannen miteinander zu kommunizieren, Daten wurden im Hintergrund synchronisiert, und die interne Koordination entwickelte sich zu einem wesentlichen Bestandteil der Gesamtlast. In diesem Moment rückte der East-West-Verkehr in eine ebenso zentrale Rolle wie der klassische nutzergetriebene Verkehr.
Dabei handelte es sich nicht nur um eine technische, sondern um eine konzeptionelle Verschiebung. Das System war nicht länger eine Pipeline, sondern ein Ökosystem. Nicht jeder Verkehr war gleichwertig, und nicht jeder Verkehr gehörte auf denselben Pfad.
Ein architektonischer Wandel
Wenn North-South- und East-West-Verkehr getrennt betrachtet werden, verändert sich die Struktur eines Systems grundlegend. Die Architektur ordnet sich nicht mehr um eine zentrale Komponente herum an, sondern beginnt sich entlang klarer Verantwortlichkeiten zu schichten. Externer Verkehr kann bereits am Rand des Systems angenommen, interpretiert und bei Bedarf begrenzt werden, bevor er Anwendungslogik oder persistente Daten belastet. Der interne Verkehr hingegen kann nach anderen Kriterien optimiert werden: Zuverlässigkeit, Konsistenz und Beobachtbarkeit rücken in den Vordergrund.
Dieser Wandel ist nicht nur technischer, sondern auch begrifflicher Natur. Wenn ein System als Zusammenspiel mehrerer Verkehrsströme verstanden wird, muss es nicht länger so tun, als wäre es ein einziges, homogenes „Backend“. Stattdessen entsteht ein mehrschichtiges Modell, in dem jede Ebene eine klar definierte Aufgabe und eine begrenzte Verantwortung trägt. Keine einzelne Schicht versucht, das gesamte Problem zu lösen; jede kümmert sich ausschließlich um ihren eigenen Anteil. Dies reduziert die interne Kopplung und macht das Gesamtsystem leichter verständlich – nicht als einzelne Box, sondern als strukturierte Gesamtheit.
Aus Sicht des Nutzers bleibt dieser Wandel meist unsichtbar. Der Nutzer interagiert nicht mehr mit „dem Backend“, sondern mit mehreren Ebenen des Systems, auch wenn sich dies in der Benutzeroberfläche nicht widerspiegelt. Die Anfrage schreitet schrittweise voran, und jede Ebene trifft ihre eigene Entscheidung darüber, ob die Anfrage überhaupt weiterverarbeitet werden sollte. In diesem Sinne ähnelt das System eher einem abwägenden Prozess als einer geradlinigen Pipeline.
Gerade diese Abwägung ist der Kern des mehrschichtigen Modells. Jede Ebene übernimmt weniger Aufgaben als ein traditionelles Backend, erfüllt diese jedoch bewusster und kontrollierter. Verantwortlichkeiten verschwinden nicht, sondern verlagern sich dorthin, wo sie effektiver wahrgenommen werden können. Architektur wird nicht komplex, weil willkürlich Schichten hinzugefügt werden, sondern weil die Realität selbst komplex ist. Schichtung ist ein Mittel, diese Komplexität sichtbar – und damit beherrschbar – zu machen.
Die Ebenen 1-6 als Gesamtheit
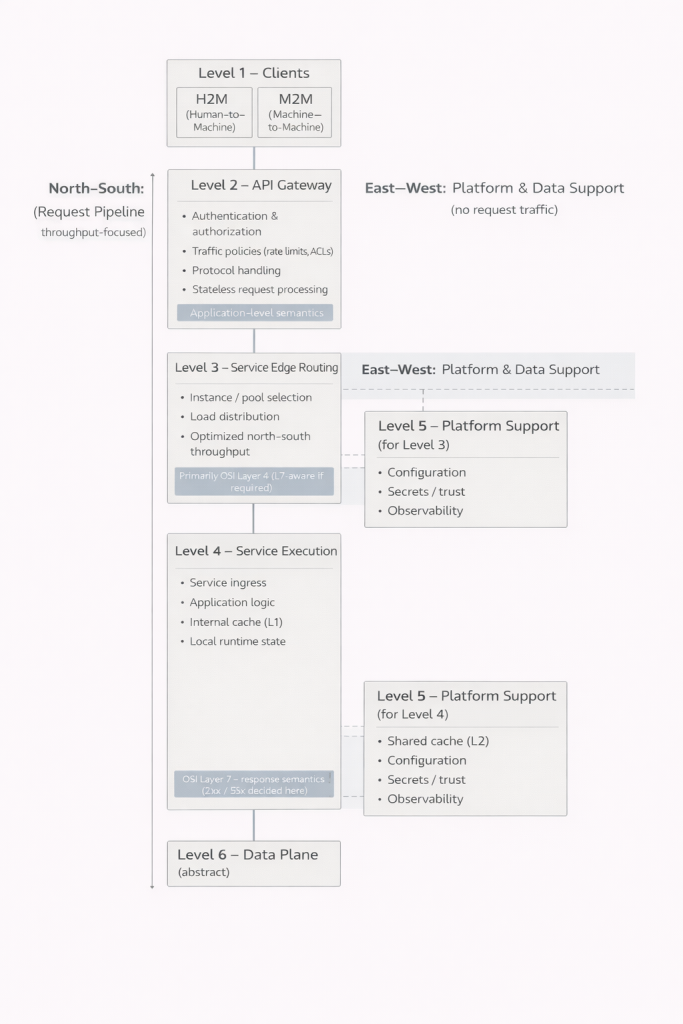
Die erste Ebene besteht aus den Clients. Menschliche Benutzeroberflächen und maschinelle Integrationen mögen von außen ähnlich wirken, ihre Anforderungen und ihr Verhalten können jedoch grundlegend verschieden sein. Diese Unterscheidung ist entscheidend, da das System beide kontrolliert bedienen muss.
Die zweite Ebene bildet die Schnittstelle zwischen System und Außenwelt. Hier finden Authentifizierung, Autorisierung, Verkehrsbegrenzung und häufig auch die Protokollverarbeitung statt. Eine zentrale Erkenntnis ist, dass nicht jede Anfrage über diesen Punkt hinaus gelangt. Ungültige Anmeldedaten, fehlende Berechtigungen oder überschrittene Limits können sofort zurückgewiesen werden. Dies entlastet die tieferen Ebenen des Systems und verbessert sowohl Performance als auch Sicherheit.
Die dritte Ebene ist für die Weiterleitung des Verkehrs zu den Diensten verantwortlich. In kleinen Systemen kann sie mit der nächsten Ebene verschmelzen und wird nicht immer explizit erkannt. Mit wachsender Nutzerzahl und steigender Anzahl von Instanzen wird sie jedoch unverzichtbar. Sie ermöglicht Lastverteilung, Fehlerisolation und kontrollierte Skalierung.
Die vierte Ebene ist der Ort, an dem die eigentliche Arbeit der Anwendung stattfindet. Geschäftslogik, Antwortgenerierung und lokale Zustandsverwaltung sind hier angesiedelt. Wichtig ist zu verstehen, dass diese Ebene kein einzelner Block sein muss. Sie kann aus mehreren parallelen Komponenten bestehen, die gemeinsam dieselbe Funktion erfüllen. Dadurch lassen sich einzelne Teile aktualisieren oder außer Betrieb nehmen, während andere weiterhin Anfragen bedienen. Für den Nutzer bleibt dies häufig unbemerkt, selbst wenn sich im Inneren des Systems erhebliche Veränderungen vollziehen.
Die fünfte Ebene bringt operative Kontrolle ins Spiel. Konfigurationen, Vertrauensbeziehungen, Geheimnisse und Beobachtbarkeit gehören nicht zur Anwendungslogik, sind jedoch Voraussetzung für einen sicheren und zuverlässigen Betrieb. In kleinen Systemen sind diese Verantwortlichkeiten oft verborgen und in andere Komponenten integriert. Mit zunehmender Systemgröße treten sie zwangsläufig als eigenständige Themen hervor.
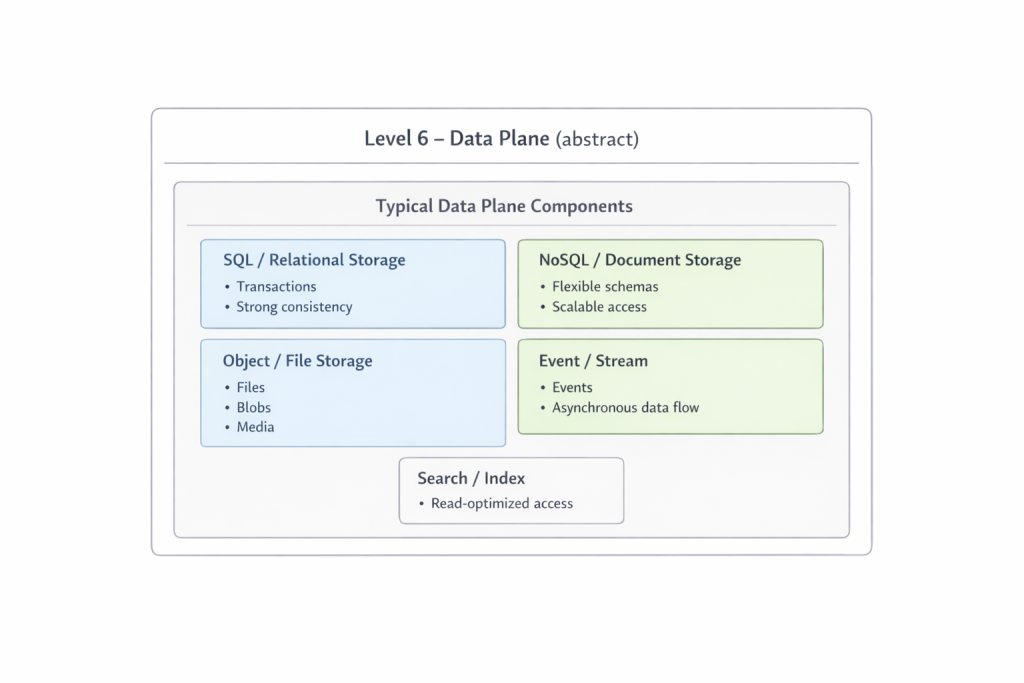
Die sechste Ebene ist die Welt der Daten. Sie wird hier bewusst abstrakt gehalten, da sie eine eigene Betrachtung verdient. Dateien, Relationen, Ereignisse und Datenströme bilden das Fundament, auf dem alles andere aufbaut. Je tiefer eine Anfrage in diese Ebene vordringt, desto teurer und langsamer wird sie in der Regel. Genau deshalb ist die Fähigkeit früherer Ebenen, Antworten bereits vorher zu liefern, ein so entscheidender Vorteil.
Performance und Skalierbarkeit
Ein häufig unterschätzter Vorteil dieses Modells besteht darin, dass nicht immer alles ausgeführt werden muss. Im klassischen Frontend-Backend-Denken durchläuft eine Anfrage oft einen großen Teil des Systems, bevor überhaupt eine Ablehnung in Betracht gezogen wird. Im neuen Modell fungiert jede Ebene als bewusster Filter, der prüft, ob es sinnvoll ist, die Anfrage an die nächste Stufe weiterzugeben. Dies ist keine bloße Optimierung, sondern eine strukturelle Eigenschaft, die das Verhalten des Systems unter Last grundlegend verändert.
Bereits am Rand des Systems können Entscheidungen getroffen werden, die eine Anfrage sofort beenden. Authentifizierung, Autorisierung und Verkehrsbegrenzung sind keine internen Anwendungsaufgaben mehr, sondern vorgelagerte Schritte, bevor überhaupt Anwendungsressourcen beansprucht werden. In der Praxis bedeutet dies, dass ungültige, unautorisierte oder missbräuchliche Anfragen die teuersten Teile des Systems nie erreichen.
Caching verstärkt dieses Prinzip zusätzlich. Kann eine Antwort direkt aus einer Rand- oder Service-Schicht geliefert werden, ohne persistente Daten zu berühren, werden Zeit und Gesamtkapazität des Systems geschont. Dies ist nicht nur eine Frage der Geschwindigkeit, sondern auch der Stabilität: Je seltener die teuersten und langsamsten Ressourcen genutzt werden, desto besser übersteht das System Lastspitzen und Ausnahmesituationen.
Skalierbarkeit ist in diesem Modell nicht länger eindimensional. Das System kann auf unterschiedlichen Ebenen unterschiedlich erweitert und verstärkt werden. Die Randebene lässt sich skalieren, um höhere Anfragevolumina zu bewältigen, ohne die Anwendungslogik anzupassen. Die Service-Ebene kann durch parallele Komponenten erweitert werden, die Last teilen und kontrollierte Updates ermöglichen. Die Datenebene kann separat optimiert werden, ohne den nutzerseitigen Verkehr direkt zu beeinflussen.
Diese mehrdimensionale Skalierung reduziert die Notwendigkeit überdimensionierter Einzelkomponenten. Anstatt dass ein einzelnes Backend unkontrolliert anwächst, verteilen sich Verantwortung und Last auf natürliche Weise. Das Ergebnis ist ein System, das nicht nur besser skaliert, sondern sich unter steigender Last auch vorhersehbarer verhält.
Verantwortung und Sicherheit
Wenn Verantwortlichkeiten klar getrennt sind, wird Sicherheit zu einer natürlichen Eigenschaft der Architektur. Im traditionellen Modell ist Sicherheit häufig eine Funktion der Anwendung: Prüfungen erfolgen dort, wo die Anfrage letztlich verarbeitet wird. Das führt dazu, dass schädlicher oder fehlerhafter Verkehr oft tief ins System eindringt, bevor er gestoppt wird.
Im mehrschichtigen Modell kehrt sich diese Dynamik um. Schädlicher Verkehr soll so früh wie möglich erkannt und unterbunden werden. Die Randebene fungiert nicht nur als Pförtner, sondern als aktive Verteidigungslinie, die die tieferen Schichten schützt. Dies reduziert die Belastung der Anwendungslogik und verringert das Risiko, dass ein einzelner Fehler oder eine Schwachstelle zu einem umfassenden Problem eskaliert.
Zero-Trust-Denken fügt sich nahtlos in dieses Bild ein. Es ist kein Zusatz und keine ideologische Entscheidung, sondern eine logische Konsequenz eines Systems, in dem keine Ebene einer anderen implizit vertraut. Jede Anfrage wird im Kontext bewertet, und Berechtigungen werden dort geprüft, wo sie die größte Wirkung entfalten. Das macht das System widerstandsfähiger gegenüber externen Angriffen ebenso wie gegenüber internen Fehlfunktionen.
Klare Verantwortungsgrenzen helfen auch auf organisatorischer Ebene. Wenn bekannt ist, welches Team für welche Ebene zuständig ist, lassen sich Probleme schneller lokalisieren und beheben. Sicherheit bleibt keine diffuse Gemeinschaftsaufgabe, sondern ist an konkrete Strukturen und Rollen gebunden.
Schwächen und Realitäten
Es muss offen gesagt werden, dass mehrschichtige Architekturen nicht ohne Nachteile sind. Sie bringen mehr bewegliche Teile, zusätzliche Schnittstellen und einen höheren Bedarf an systemischem Verständnis mit sich. Fehlkonfigurationen, unklar definierte Grenzen oder verschwommene Verantwortlichkeiten können Situationen erzeugen, in denen Probleme schwerer zu erkennen sind als in einfacheren Modellen.
Frühe Entscheidungsfindung bedeutet zudem zwangsläufig Entscheidungen auf Basis begrenzten Kontexts. Zu aggressive Verkehrsbegrenzung oder falsch konfigurierte Caches können legitimen Verkehr blockieren oder fehlerhafte Antworten liefern. Diese Risiken sind real und dürfen nicht bagatellisiert werden.
Der Unterschied zum traditionellen Modell besteht jedoch nicht darin, dass Probleme verschwinden, sondern darin, wo und wie sie auftreten. In mehrschichtigen Systemen sind Probleme oft sichtbarer und besser eingegrenzt. Sie lassen sich einer bestimmten Ebene zuordnen und beheben, ohne das gesamte System anhalten oder neu starten zu müssen. Langfristig macht dies das System trotz seiner strukturellen Komplexität leichter beherrschbar.
Schlussbemerkungen
Das Frontend-Backend-Modell ist nicht falsch, aber es reicht nicht aus, um die Realität moderner Systeme zu beschreiben. Es ist ein guter Einstieg, aber ein schlechter Endpunkt. Betrachtet man Systeme als Zusammenspiel von Schichten und Verantwortlichkeiten, entsteht ein tieferes und realistischeres Verständnis davon, wie Performance, Sicherheit und Skalierbarkeit tatsächlich entstehen.
Frontend-Backend ist nicht deshalb überholt, weil es versagt hätte, sondern weil es erfolgreich war. Es hat seine Aufgabe als notwendiger Entwicklungsschritt erfüllt. In einer Welt komplexerer Systeme und höherer Anforderungen ist es nun an der Zeit, zur nächsten Abstraktion überzugehen – zu einer, die die Komplexität der Realität nicht scheut, sondern beherrschbar macht.
Eine der unbequemeren Konsequenzen dieses Modells besteht darin, dass es auch die klassische Frontend-Backend-Trennung begrifflich aufbricht. Wird Frontend-Code vom Server ausgeliefert, ist er keine architektonische Ausnahme, sondern Teil desselben Verkehrsflusses wie jede andere Ressource. Er durchläuft dieselbe Request-Pipeline, unterliegt denselben Authentifizierungs-, Caching- und Verkehrssteuerungsmechanismen und ist denselben Sicherheits- und Performanceentscheidungen ausgesetzt wie jede andere Antwort. In diesem Sinne ist das Frontend keine eigenständige Schicht, sondern eines von vielen serverseitig erzeugten Artefakten.
Gerade diese Sichtweise stößt oft auf Widerstand, weil sie sichtbar macht, was zuvor ausgeblendet werden konnte. Wird das Frontend als Teil derselben Pipeline verstanden, wird sein Einfluss auf Performance und Sicherheit unausweichlich. Die Auslieferung statischen Codes ist keine kostenlose Randnotiz, sondern eine lastverursachende Operation, die entweder effizient am Rand des Systems abgefangen oder unnötig durch die Anwendungsschicht geschleust wird. Gleichzeitig wird die Frontend-Auslieferung zu einer Sicherheitsfrage: falsch versionierter, schlecht gecachter oder zu weit freigegebener Code stellt ein ebenso reales Risiko dar wie eine fehlerhafte Backend-Antwort.
Im neuen Modell ist dies kein Problem, sondern Absicht. Wird das Frontend in dieselbe Struktur integriert wie andere Antworten, profitiert es von denselben Schutzmechanismen und Optimierungen. Schädlicher oder fehlerhafter Verkehr kann gestoppt werden, bevor er die Anwendungslogik erreicht, und wiederholte Ressourcenanfragen lassen sich bedienen, ohne die teuersten Komponenten des Systems zu berühren. Das Frontend verliert nicht seine Rolle als Benutzeroberfläche, aber es verliert seine architektonische Sonderstellung – und genau das macht das System schneller, sicherer und ehrlicher beschreibbar.
Das in diesem Artikel dargestellte Modell ist bewusst auf einer allgemeinen und konzeptionellen Ebene gehalten. Sein Ziel ist es nicht, bereits eine konkrete Implementierung vorzuschreiben, sondern die Art und Weise zu verändern, wie Systeme grundsätzlich gedacht werden. Jede der beschriebenen Ebenen trägt eigene Verantwortlichkeiten, Risiken und Potenziale, und ihr Verständnis erfordert mehr als eine oberflächliche Betrachtung. Aus diesem Grund werden in zukünftigen Artikeln diese Ebenen einzeln, in Ruhe und isoliert betrachtet, um ihre Rollen, Grenzen und praktischen Konsequenzen detaillierter zu beleuchten.
In diesen kommenden Texten wird das konzeptionelle Modell auch mit konkreteren Beispielen verankert. Code, Container und einfache Implementierungsmuster dienen dazu, zu zeigen, wie sich dieselben Prinzipien in der Praxis widerspiegeln, ohne den Fokus auf einzelne Technologien zu verengen. Ziel ist es nicht, ein fertiges Rezept zu liefern, sondern sichtbar zu machen, wie architektonische Entscheidungen reale Systeme prägen.
Insbesondere die sechste Ebene, die sogenannte Data Plane, ist hier bewusst abstrakt geblieben. Sie ist keine Randbemerkung, sondern ein Themenfeld, das einen eigenen Raum und einen eigenen Denkrahmen erfordert. In weiteren Artikeln wird untersucht, wie diese Gesamtheit technisch zu einem kohärenten System geformt werden kann, ohne eine Organisation in einen einzigen Monolithen zu zwingen. Strukturelle Einheit und organisatorische Dezentralisierung sind keine Gegensätze, sondern eine zentrale Spannung moderner Architektur. Diese Spannung zu verstehen ist Voraussetzung dafür, das Modell von einer Zeichnung in ein funktionierendes System zu überführen.