Garbage Collector – Che cos’è e perché ogni sviluppatore dovrebbe comprenderlo
La maggior parte degli sviluppatori si è trovata almeno una volta in una situazione in cui un’applicazione inizia a comportarsi in modo anomalo senza una causa evidente. Il consumo di memoria cresce gradualmente, i tempi di risposta peggiorano e, a un certo punto, qualcuno propone di riavviare il servizio. Spesso questo aiuta, almeno temporaneamente. Il problema, tuttavia, raramente viene risolto. Semplicemente scompare dalla vista per poi riemergere più tardi, magari in una forma diversa o sotto un carico maggiore.
Sorprendentemente spesso l’attenzione si concentra sui punti sbagliati. Si cercano errori negli algoritmi, nei database o nel livello di rete, anche se il vero fattore esplicativo è molto più fondamentale. Il problema è che lo sviluppatore non comprende pienamente ciò che il runtime del linguaggio sta facendo al suo posto. Uno dei componenti più critici, e al tempo stesso meno compresi, di questo runtime è il garbage collector.
Il garbage collector non è un dettaglio marginale di implementazione né una funzionalità accessoria. In molti linguaggi è una parte centrale del modello di esecuzione. Se non lo si comprende, non si può comprendere davvero nemmeno il comportamento di un’applicazione in produzione.
Che cos’è realmente un garbage collector
La garbage collection viene spesso descritta come se fosse un processo in background che, di tanto in tanto, libera la memoria non utilizzata. La metafora è suggestiva, ma fuorviante. Un garbage collector non è né un assistente invisibile né una comodità gratuita. È un sistema attivo del runtime che prende decisioni per conto del programma.
In concreto, il garbage collector decide quando la memoria viene liberata. Non chiede il permesso allo sviluppatore né segue le intenzioni implicite espresse nel codice. Opera secondo un proprio modello e sulla base di euristiche. Utilizzando un linguaggio con garbage collection, lo sviluppatore rinuncia al controllo diretto sul momento della liberazione della memoria. In cambio ottiene maggiore sicurezza, uno sviluppo più rapido e l’eliminazione di un’intera classe di errori legati alla gestione della memoria.
Questo non è un difetto né una debolezza. È un compromesso consapevole. Ciò che conta è capire che la responsabilità non scompare, ma si sposta dallo sviluppatore al sistema di esecuzione.
Perché la garbage collection è stata introdotta
In assenza di un garbage collector, lo sviluppatore è responsabile di ogni allocazione e di ogni deallocazione della memoria. Questo modello è efficiente e prevedibile, ma cognitivamente impegnativo. Un singolo errore può causare perdite di memoria, doppie liberazioni o riferimenti a memoria già liberata. Errori di questo tipo raramente si manifestano subito; spesso emergono solo sotto carico in produzione e, nei casi peggiori, in modo non deterministico.
La garbage collection è stata introdotta proprio per affrontare questi problemi. Il suo obiettivo era rendere praticabili sistemi software grandi, longevi e complessi senza richiedere a ogni sviluppatore una padronanza completa della gestione della memoria a basso livello. Allo stesso tempo, i linguaggi di programmazione potevano offrire garanzie di sicurezza più forti.
Il costo di questo approccio è evidente. Una volta che il momento della liberazione della memoria viene delegato al runtime, il comportamento del programma non è più completamente deterministico. Lo sviluppatore non può più stabilire con precisione quando la memoria verrà liberata. Può solo influenzare questo momento in modo indiretto.
Come il garbage collector “vede” il tuo codice
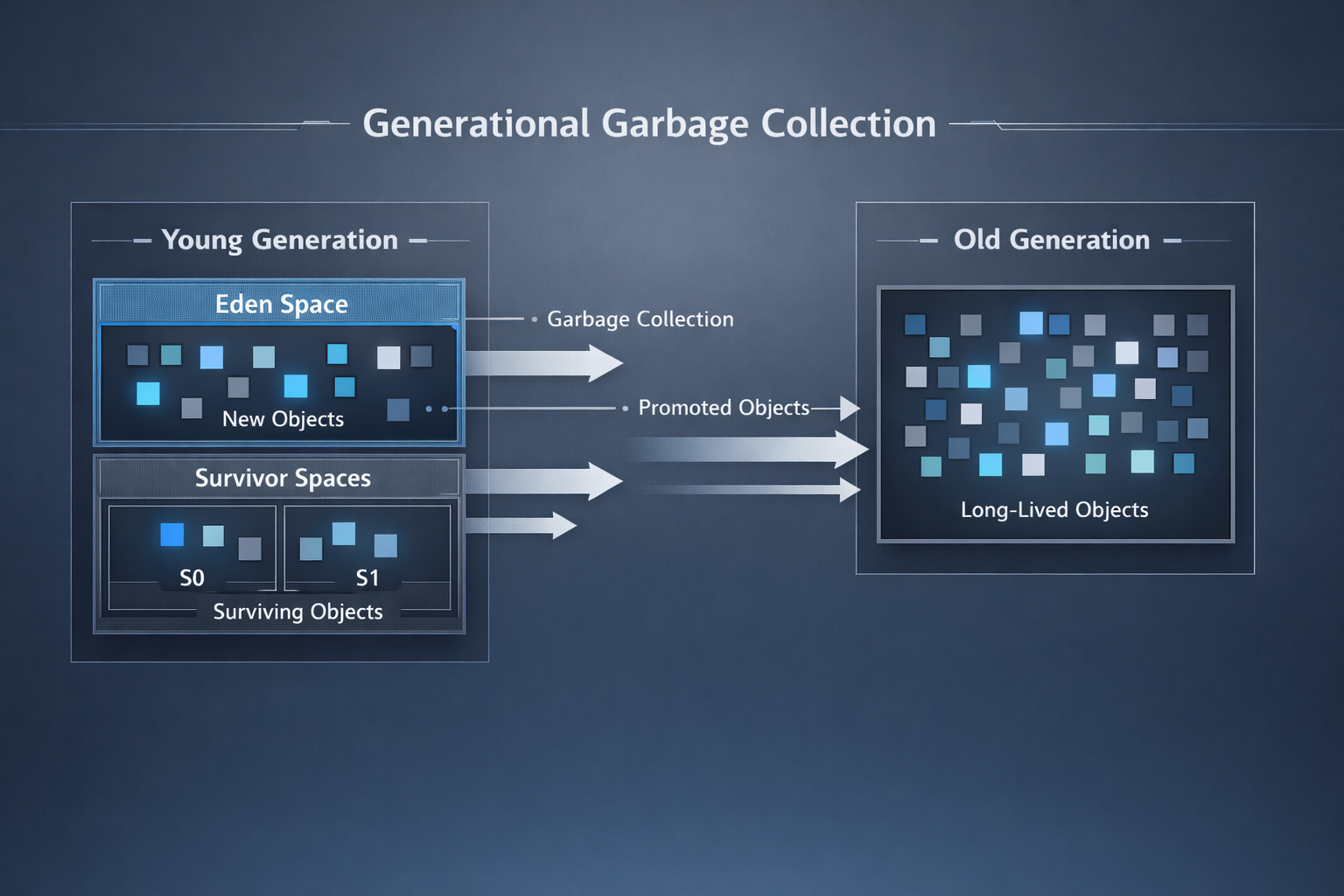
A questo punto è importante capire che un garbage collector non tratta normalmente tutta la memoria allo stesso modo. La maggior parte dei collector moderni si basa su quella che viene chiamata ipotesi generazionale. L’assunto è semplice ma empiricamente efficace: la maggior parte degli oggetti muore giovane, mentre solo una piccola frazione vive a lungo.
Per questo motivo, la memoria viene tipicamente suddivisa in generazioni. Gli oggetti giovani vengono raccolti frequentemente mediante cicli leggeri, mentre quelli di lunga durata vengono promossi in aree più vecchie, analizzate meno spesso ma con operazioni più costose. Di conseguenza, non tutti i cicli di garbage collection sono uguali. Alcuni sono rapidi e quasi impercettibili; altri sono più rari ma chiaramente visibili.
Dal punto di vista dello sviluppatore, questo spiega perché certi modelli di allocazione sembrano “economici”, mentre altri producono improvvisamente ritardi significativi. Non si tratta di un comportamento casuale, ma della conseguenza di quanto le durate di vita degli oggetti si allineino — o meno — con le assunzioni del collector.
Allo stesso tempo, gli sviluppatori spesso cadono in un’errata assunzione fondamentale. È facile pensare che il garbage collector comprenda il significato del codice o l’intenzione dello sviluppatore. In realtà, non comprende né la logica di business né la semantica, né quando qualcosa non è più “concettualmente” necessario.
Il garbage collector comprende le referenze. Se un oggetto è raggiungibile, è considerato vivo. Se non lo è, è considerato spazzatura. Questo è l’intero modello, senza alcun elemento misterioso.

Ciò porta a situazioni che spesso sorprendono gli sviluppatori. Una singola referenza non intenzionale può mantenere in vita un intero grafo di oggetti. Nei linguaggi con garbage collection, una cosiddetta perdita di memoria non significa di solito che la memoria non venga mai liberata, ma che gli oggetti rimangono raggiungibili più a lungo del previsto. Una volta compreso questo meccanismo, molti problemi che prima apparivano enigmatici iniziano a presentarsi come conseguenze logiche
Lo stesso problema, linguaggi diversi, responsabilità diverse
Sebbene l’idea di base della garbage collection sia coerente, i diversi linguaggi distribuiscono la responsabilità in modi molto differenti.
Java e Go sono progettati fin dall’inizio attorno alla garbage collection. Gli sviluppatori possono allocare oggetti liberamente e il runtime si occupa della liberazione. Questo porta spesso a codice più pulito e a uno sviluppo più rapido, ma sposta anche parte del controllo delle prestazioni lontano dalle mani dello sviluppatore. Il collector prende decisioni sulla base di euristiche globali, non nel contesto di singole richieste. Il risultato sono pause, picchi di memoria e, talvolta, un comportamento difficile da prevedere.
Queste pause sono comunemente chiamate eventi stop-the-world. Durante uno di questi eventi, l’esecuzione normale del programma viene temporaneamente interrotta affinché il garbage collector possa operare in sicurezza. Tutti i thread dell’applicazione vengono messi in pausa, la memoria viene analizzata e l’esecuzione riprende solo successivamente. La durata di queste pause può variare da quasi impercettibile a diversi millisecondi o più, a seconda del carico e della strategia di GC. Nell’ecosistema JVM, una parte significativa dell’ottimizzazione delle prestazioni ruota proprio attorno alla riduzione di questi intervalli stop-the-world o al loro spostamento lontano dai percorsi critici in termini di latenza.

Non si tratta di una condizione eccezionale né di uno stato di errore, ma di una componente deliberata del modello di garbage collection. Una volta compreso questo aspetto, i picchi di latenza cessano di essere misteriosi e diventano il risultato di scelte di progettazione specifiche.
In JavaScript, la garbage collection è sempre presente ma facilmente trascurata. TypeScript rafforza ulteriormente questa illusione. Sebbene TypeScript migliori l’esperienza dello sviluppatore e la sicurezza dei tipi, non modifica in alcun modo il runtime. La gestione della memoria si comporta esattamente come in JavaScript. TypeScript cambia il modo in cui gli sviluppatori pensano, non il modo in cui i programmi vengono eseguiti, e dimenticarlo porta spesso a una falsa sensazione di controllo.
Python e PHP rappresentano modelli ibridi, che combinano il conteggio delle referenze con la garbage collection. Parte della memoria viene liberata immediatamente, mentre un’altra parte viene rilasciata solo durante i cicli di GC. Questo crea l’impressione di un maggiore determinismo, ma in realtà il comportamento è più complesso. I diversi ambienti di esecuzione si comportano in modo diverso e le assunzioni su quando la memoria venga liberata si rivelano frequentemente errate.
C++ e Rust offrono un contrasto significativo. In C++, lo sviluppatore si assume la piena responsabilità della gestione della memoria, il che consente un comportamento prevedibile al costo di potenziali errori. Rust porta questa idea oltre, spostando la responsabilità nel sistema di tipi e nei controlli a tempo di compilazione. Proprietà (ownership) e tempi di vita (lifetimes) costringono gli sviluppatori a ragionare esplicitamente sulle stesse questioni che i garbage collector gestiscono automaticamente in altri linguaggi. L’assenza di un garbage collector non rende un linguaggio obsoleto; rende la responsabilità esplicita.
Perché è essenziale comprendere la garbage collection
Anche se non si ottimizza mai codice di basso livello o non si costruiscono sistemi in tempo reale, la garbage collection influisce comunque direttamente sul lavoro quotidiano. Incide sui tempi di risposta, sul consumo di memoria e sul comportamento dei sistemi sotto carico. Molti problemi in produzione che appaiono enigmatici sono, in realtà, conseguenze del comportamento del garbage collector.
Quando gli sviluppatori comprendono la garbage collection, iniziano a guardare i problemi in modo diverso. Il debugging si sposta dai sintomi alle cause profonde. Le decisioni architetturali diventano più consapevoli e i problemi di prestazioni si collocano in un contesto più ampio.
Quando si considerano insieme le pause stop-the-world e il modello generazionale, emerge un quadro coerente che spiega perché i garbage collector si comportano come si comportano. Il GC non è arbitrario; ottimizza rispetto a una realtà statistica. I problemi sorgono quando le durate di vita reali degli oggetti di un’applicazione divergono in modo significativo da ciò che il runtime assume.
In questo senso, il garbage collector agisce come uno specchio. Non crea problemi dal nulla; li rende visibili.
Conclusione
Il garbage collector non è un nemico, ma non è nemmeno un meccanismo magico. È una scelta architetturale che sposta il processo decisionale dallo sviluppatore al sistema di esecuzione. Una volta compreso questo spostamento, molte domande sul comportamento dei programmi iniziano ad avere risposte chiare.
La garbage collection non libera lo sviluppatore dalla gestione della memoria. Cambia semplicemente dove e quando vengono prese queste decisioni. Se questo spostamento non viene compreso, la natura reale del software rimane parzialmente oscura. Se invece viene compreso, il comportamento dei sistemi complessi appare improvvisamente molto più coerente – e decisamente meno misterioso.





